

Künstliche Intelligenz hat uns mit dem Stille-Post-Spiel ausgetrickst … und das Ergebnis war schockierend!
KI-gestützte Modelle zur Bildgenerierung entwickeln sich schnell weiter, doch es kommt immer noch häufig vor, dass sie fragwürdige Bilder produzieren. Da man leicht annehmen könnte, dass menschliche Eingabeaufforderungen das Problem sind, habe ich beschlossen zu testen, ob KI einfacher funktioniert, wenn nur von KI generierte Eingabeaufforderungen verwendet werden. Der Prozess der Bildgenerierung mit künstlicher Intelligenz, wie ChatGPT und Gemini, hängt stark von der Qualität und Genauigkeit der Eingabeaufforderungen ab. Werden die Ergebnisse bei der Verwendung automatisierter Ansprüche anders ausfallen? Dies werden wir in diesem Experiment herausfinden.
![]()
Faustregeln
Als vor einigen Jahren KI-Modelle zur Bildgenerierung aufkamen, dachten wir alle, dies wäre ein Weckruf für alle, die in den visuellen Medien arbeiten. Aber es war nicht so. Trotz ihrer Fähigkeit, äußerst realistische Bilder zu erstellen, fallen KI-Bilder häufig in die Kategorie „Unerwartet“, insbesondere wenn Sie etwas Komplexeres benötigen (beispielsweise hat KI tendenziell Schwierigkeiten, Bilder von Händen zu generieren).
Sie können die Schuld für dieses Problem entweder den KI-Modellen selbst oder den Unzulänglichkeiten des Menschen und unseren inkonsistenten Fähigkeiten beim Formulieren von Ansprüchen zuschreiben. Eine natürliche Möglichkeit, zu testen, wer verantwortlich ist, besteht darin, zu prüfen, ob Bildgenerierungsmodelle bessere Ergebnisse liefern, wenn Sie generierte Eingabeaufforderungen einführen.

Kann uns KI neue Perspektiven auf historische Momente eröffnen?
Um diese Hypothese zu testen, werde ich Gemini verwenden, um eine Reihe von Eingabeaufforderungen zu erstellen, die die Verwendung des Namens des Objekts oder Bildes vermeiden, das ich erstellen möchte. Dadurch lässt sich überprüfen, wie gut die KI die Anweisungen „liest“. Zugegebenermaßen besteht immer noch die Möglichkeit, dass das Modell erhebliche Inspiration aus den Daten zieht, mit denen es trainiert wurde (insbesondere bei der Neuerstellung vorhandener Bilder), aber das ist die Realität, sagt Young.
Mein bevorzugtes Tool zum Erstellen von Bildern ist der Image Creator von Bing (ja, Bing gibt es noch), der auf DALL-E 3 basiert. Um das Modell zu testen, beginne ich mit einfachen Formen und gehe im Verlauf des Experiments zu komplexeren Bildern über.
Wenn Sie ChatGPT und ähnliche Programme verwendet haben, wissen Sie bereits, wie nutzlos einige der Antworten sein können. Und bei den Eingabeaufforderungen, die mir das Modell während eines „Beta“-Laufs stellte, war es nicht anders. Aus diesem Grund habe ich beschlossen, mich auf 500 Zeichen zu beschränken, um die Konsistenz der Eingabeaufforderungen zu wahren.
Wie KI mit einfachen Formen umgeht
Beginnen wir mit einem einfachen Quadrat. Ich bat Gemini, ein Quadrat zu beschreiben, ohne ihm einen Namen zu geben, und er kam auf Folgendes:
Ein Viereck, bei dem alle Seiten gleich lang sind. Jeder Innenwinkel misst genau 90 Grad. Es ist ein regelmäßiges Viereck mit parallelen gegenüberliegenden Seiten.
Nachdem ich die Beschreibung in DALL-E eingegeben hatte, erhielt ich diese Ergebnisse:
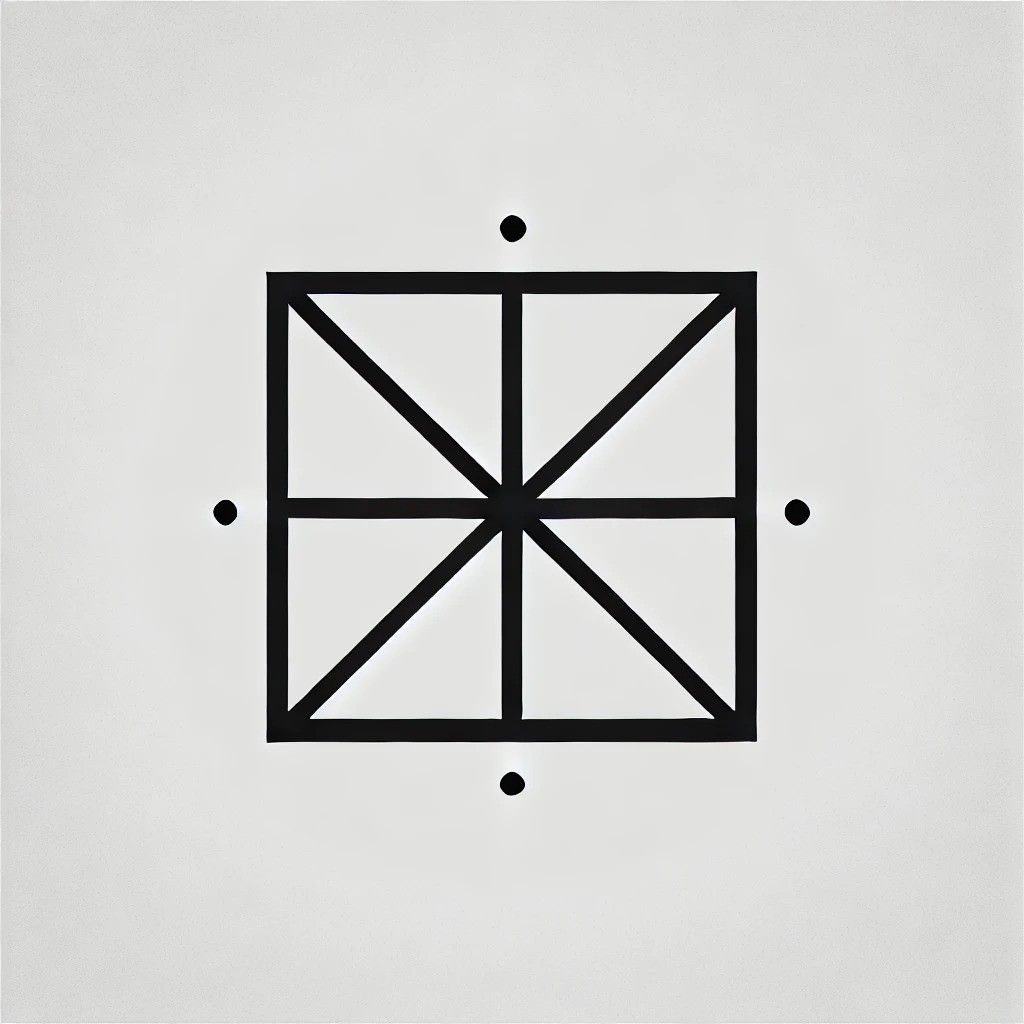
Es ist ein Quadrat, okay, obwohl ich denke, dass das ein bisschen zu geometrisch ist. Es war Zeit, den Schwierigkeitsgrad zu erhöhen, also bat ich die KI, einen Würfel zu detaillieren.
Eine dreidimensionale Form mit sechs kongruenten Flächen. Jede Fläche ist ein regelmäßiges Viereck mit vier gleich langen Seiten und vier rechten Winkeln. Es hat 12 gleich lange Kanten und 8 Eckpunkte. Alle Winkel innerhalb der Form sind rechte Winkel.
Die Ergebnisse sind erstaunlich:

Erinnern Sie sich, was wir über die Unvorhersehbarkeit von KI-Modellen gesagt haben? Nun, hier hat DALL-E einen Würfel erstellt, war dabei aber etwas verwirrt und hat daraus einen Zauberwürfel gemacht. Obwohl die KI das genaue Wort völlig vermied, hat sie es teilweise falsch verstanden – wir können dies auf die Popularität des galaktischen Puzzlespiels zurückführen.
KI-Ansatz zur Fotografie mit Menschen
Die Würfelsituation zeigt, dass KI selbst bei einer genauen, „unvoreingenommenen“ Beschreibung ziemlich einfache Anweisungen falsch interpretieren kann. Sehen wir uns also an, wie gut es bei KI-generierten Beschreibungen klassischer Bilder wie „Migrant Mother“ von Dorothea Lange funktioniert. Hier ist das Originalbild:

Man sieht eine Frau, deren Gesicht von Sorge gezeichnet ist, den Blick von der Kamera weg richten. Ihre Kinder umgeben sie, ihre Gesichter sind verborgen oder abgewandt. Ihre Hand liegt dicht vor ihrem Gesicht und drückt Erschöpfung und Kummer aus. Die Szene suggeriert Armut und Leid. Die Kleidung der Frau ist schäbig und die Gesamtkomposition ist düster, was den Ernst ihrer Lage unterstreicht.
Dies ist DALL-E’s Vision des berühmten Bildes:

So nah! Aber es ist nicht ganz richtig, da DALL-E den Satz „Umgeben von ihren Kindern, deren Gesichter verborgen oder abgewandt sind.Anstatt dass die „Mutter“ ihre Hand vor ihr Gesicht hielt, übernahm eines der Kinder diese Rolle.
Versuchen wir etwas Komplizierteres. Vielleicht haben Sie das berühmte Foto „Mittagessen auf einem Wolkenkratzer“ gesehen:

Elf Männer sitzen hoch oben auf einem Stahlträger und essen ihr Mittagessen. Ihre Beine baumeln. Der Träger schwebt über einer weitläufigen Stadt. Die Männer wirken trotz der extremen Höhe entspannt. Sie tragen Businesskleidung, und die Szene wurde aus einem etwas niedrigeren Winkel gedreht, um die Höhe zu betonen.
Diese wunderbare Behauptung hat wunderbare Ergebnisse hervorgebracht:

Wenn man die klassischen Merkmale eines KI-generierten Bildes (identische Töpfe und „kopierte und eingefügte“ Motive) außer Acht lässt, wird es hinsichtlich der Komposition und des Gesamteindrucks beinahe überraschend. Das ist allerdings nicht überraschend – dieses Bild ist nicht nur extrem verbreitet, sondern auch gemeinfrei, sodass ich den leisen Verdacht habe, dass DALL-E während des Trainings tatsächlich dessen Inhalt wiederhergestellt hat.
Kann KI komplexe Bilder verarbeiten?
Da dies der letzte „Test“ des Experiments ist, wird es Zeit, ernst zu werden! Während KI gut mit menschlichen Bildern umgehen kann, versagt sie häufig bei komplexen und mehrdeutigen Szenen. Und was ist mit dem berühmten „Earthrise“-Foto, das aus der Mondumlaufbahn von Apollo 8 aufgenommen wurde?

Eine teilweise beleuchtete Kugel schwebt im dunklen Raum. Eine kleinere, graue Kugel erhebt sich über ihren Horizont. Die größere Kugel zeigt blaue und weiße Flecken, die an Wasser und Wolken erinnern. Der starke Kontrast zwischen den beiden Kugeln und der Schwärze betont die Zerbrechlichkeit und Isolation der kleineren, aufsteigenden Kugel.
Gemini (oder besser gesagt Ball) erfüllt diese Beschreibung nicht. Da es zu abstrakt war, habe ich der Behauptung den Satz „aus der nahen Mondumlaufbahn aufgenommen“ hinzugefügt, aber das hat nicht viel geholfen:

Es ist ein cooles Progressive-Rock-Albumcover, hat aber nichts mit Earthrise zu tun. Zum Abschluss des Experiments habe ich das bisher geheimnisvollste Bild ausgewählt, Edward Westons industrielles Meisterwerk „Armco Steel“:

Eine Reihe runder industrieller Metalltanks füllt den Rahmen. Ihre weichen, bauchigen Formen bilden ein sich wiederholendes Muster. Licht wird von den Oberflächen reflektiert, hebt die geschwungenen Formen hervor und erzeugt ein Gefühl von Volumen. Die Komposition konzentriert sich auf die abstrakten Aspekte industrieller Objekte und betont Form und Textur statt Funktion. Die Szene ist schlicht und modern, mit einer starken Betonung von Licht und Schatten.
Das scheint ein guter Eintrag zu sein. Mal sehen, ob Dall-E uns zustimmt:

Obwohl ich das Science-Fiction-Feeling schätze, hat es überhaupt keine Ähnlichkeit mit dem Original. Ich wollte das Experiment nicht mit einem völligen Misserfolg beenden und beschloss daher, der Maschine zu helfen, indem ich am Ende des Eintrags den Begriff „Fotografie aus den 1920er Jahren“ hinzufügte.
Ich dachte, dass dieser spezielle Begriff dazu beitragen könnte, das Bild, auf das ich mich bezog, zu verdeutlichen. Leider hat mich Dall-E erneut enttäuscht und ein weiteres Progressive-Rock-Albumcover erstellt:

Die Ergebnisse dieses Experiments waren interessant und wir können daraus den Schluss ziehen, dass die KI-basierte Bildgenerierung höchst unvorhersehbar ist, insbesondere bei abstrakteren Konzepten. Dabei spielt es keine Rolle, ob die Eingabe von einer KI generiert wird und genau ist oder von einem Menschen erstellt wird und fehlerhaft ist – die Ergebnisse wirken zufällig.
Wenn Sie also das nächste Mal versuchen, sich selbst und Ihrem Eingabestil die Schuld zu geben, denken Sie daran, dass die Ergebnisse wahrscheinlich ziemlich ähnlich sein werden, selbst wenn zwei Geräte miteinander kommunizieren.
Kommentarfunktion ist geschlossen.