

Verbessern der Erkennung in Transformer-Modellen durch Hinzufügen von Trainingsrauschen
Moderne Transformer-Vision-Modelle fügen Rauschen hinzu, um die Leistung der 2D- und 3D-Objekterkennung zu verbessern. In diesem Artikel erfahren wir, wie dieser Mechanismus funktioniert, und diskutieren seinen Beitrag zur Verbesserung der Genauigkeit von Objekterkennungsmodellen. Dabei konzentrieren wir uns auf die Verwendung von Techniken wie Rauschunterdrückung im Trainingsprozess.

Transformatormodelle für frühes Sehen
DETR – DEtection TRansformer (Carion, Massa et al. 2020), eine der ersten Transformer-Architekturen zur Objekterkennung, verwendete gelernte Encoder-Decoder-Abfragen, um Erkennungsinformationen aus Bild-Token zu extrahieren. Diese Abfragen wurden zufällig initialisiert und die Architektur legte keine Einschränkungen auf, die diese Abfragen zum Erlernen ankerähnlicher Objekte zwangen. Während es mit Faster-RCNN ähnliche Ergebnisse erzielte, bestand sein Nachteil in der langsamen Konvergenz – für das Training waren 500 Epochen erforderlich (DN-DETR, Li et al., 2024). Neuere DETR-basierte Architekturen verwendeten verformbares Pooling, das es ermöglichte, dass sich Abfragen nur auf bestimmte Bereiche im Bild konzentrierten (Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020), während andere (Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022) räumliche Anker verwendeten (generiert mit k-Means, auf ähnliche Weise wie ankerbasierte CNNs), die in den ersten Abfragen kodiert wurden. Die Sprungverbindungen zwingen den Transformer-Decoderblock, die Quadrate als Steigungswerte von den Ankern zu lernen. Verformbare Aufmerksamkeitsebenen verwendeten vorcodierte Anker, um räumliche Merkmale aus dem Bild zu entnehmen und diese zum Generieren von Aufmerksamkeitstoken zu verwenden. Während des Trainings lernt das Modell, welche Anker ideal sind. Dieser Ansatz bringt dem Modell bei, Merkmale wie die Boxgröße explizit in seinen Abfragen zu verwenden.
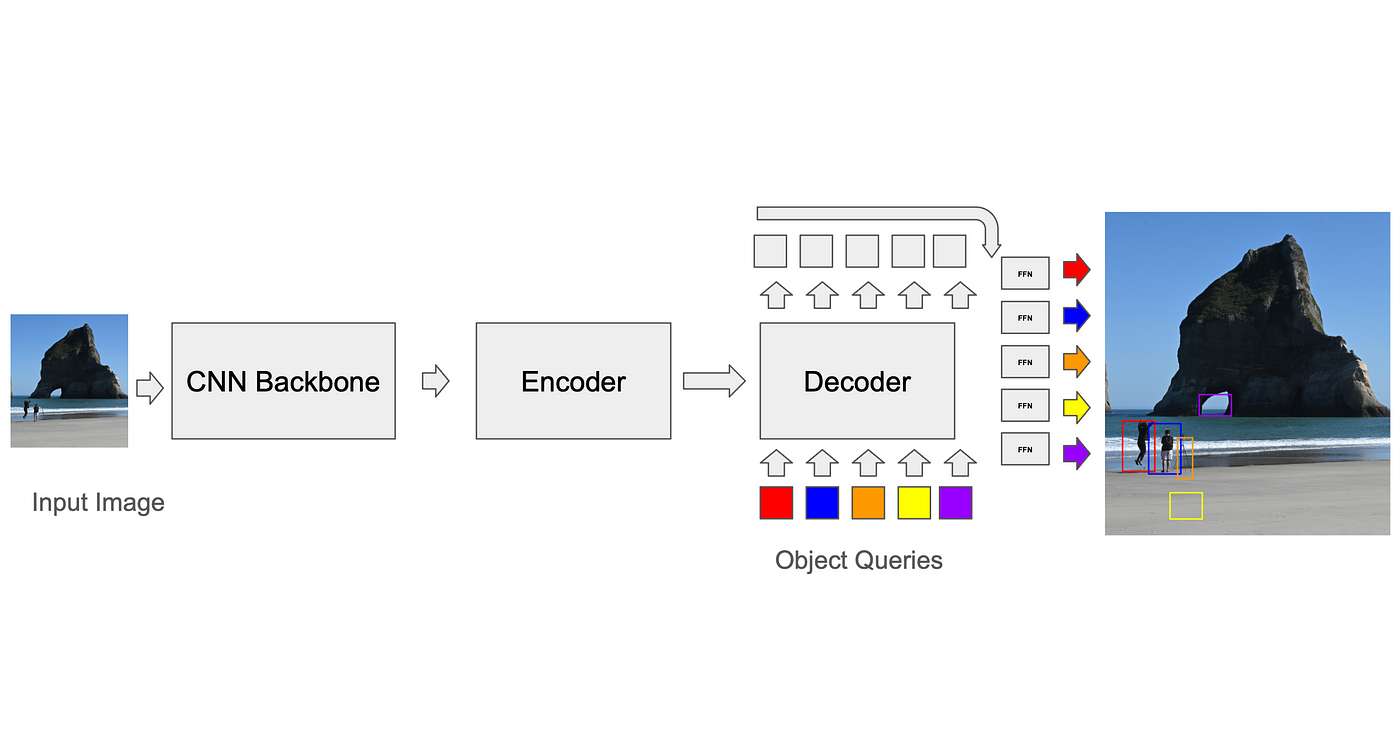
Abgleich von Vorhersagen mit Fakten: Binärer Abgleichalgorithmus
Um den Verlust zu berechnen, muss der Trainer zunächst die Vorhersagen des Modells mit den Ground Truth (GT)-Boxen abgleichen. Während ankerbasierte CNNs relativ einfache Lösungen für dieses Problem bieten (z. B. kann jeder Anker während des Trainings nur mit GT-Boxen in seinem Voxel abgeglichen werden und bei der Inferenz wird eine nicht-maximale Unterdrückung verwendet, um überlappende Erkennungen zu entfernen), besteht der von DETR entwickelte Standard für Transformatoren in der Verwendung eines binären Abgleichalgorithmus namens „Ungarischer Algorithmus“. Bei jeder Iteration findet der Algorithmus die beste Übereinstimmung zwischen der Vorhersage und der Grundwahrheit (eine Übereinstimmung, die eine Kostenfunktion optimiert, wie etwa die mittlere quadrierte Entfernung zwischen den Ecken der Boxen, summiert über alle Boxen). Der Verlust zwischen den Prädiktor-Ground-Truth-Paaren wird dann berechnet und kann zurückpropagiert werden. Überprognosen (Vorhersagen ohne GT-Übereinstimmung) führen zu einem diskreten Verlust, der sie dazu veranlasst, ihren Vertrauenswert zu reduzieren. Dieser Prozess ist notwendig, um die Genauigkeit des Modells zu verbessern und Fehler zu reduzieren.
das Problem
Die Zeitkomplexität des ungarischen Algorithmus beträgt o(n³). Interessanterweise ist dies nicht unbedingt ein Engpass in der Trainingsqualität: „The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective“, Fenoaltea et al., 2021, zeigt, dass der Algorithmus instabil ist, was bedeutet, dass eine kleine Änderung seiner Zielfunktion zu einer großen Änderung seines Matching-Ergebnisses führen kann – was zu inkonsistenten Trainingszielen für Abfragen führt. Die praktischen Auswirkungen des Transformer-Trainings bestehen darin, dass Objektabfragen zwischen Objekten springen können und es lange dauert, die besten Funktionen für die Konvergenz zu erlernen. Mit anderen Worten: Die Instabilität des Algorithmus führt zu Schwankungen im Trainingsprozess, wodurch es länger dauert, bis die besten Ergebnisse erzielt werden.
DN-DETR (Objekterkennung durch Rauschunterdrückung)
Li et al. schlug eine elegante Lösung für das Problem der instabilen Übereinstimmung vor, die später in vielen anderen Arbeiten übernommen wurde, darunter DINO, Mask DINO, Group DETR und andere.
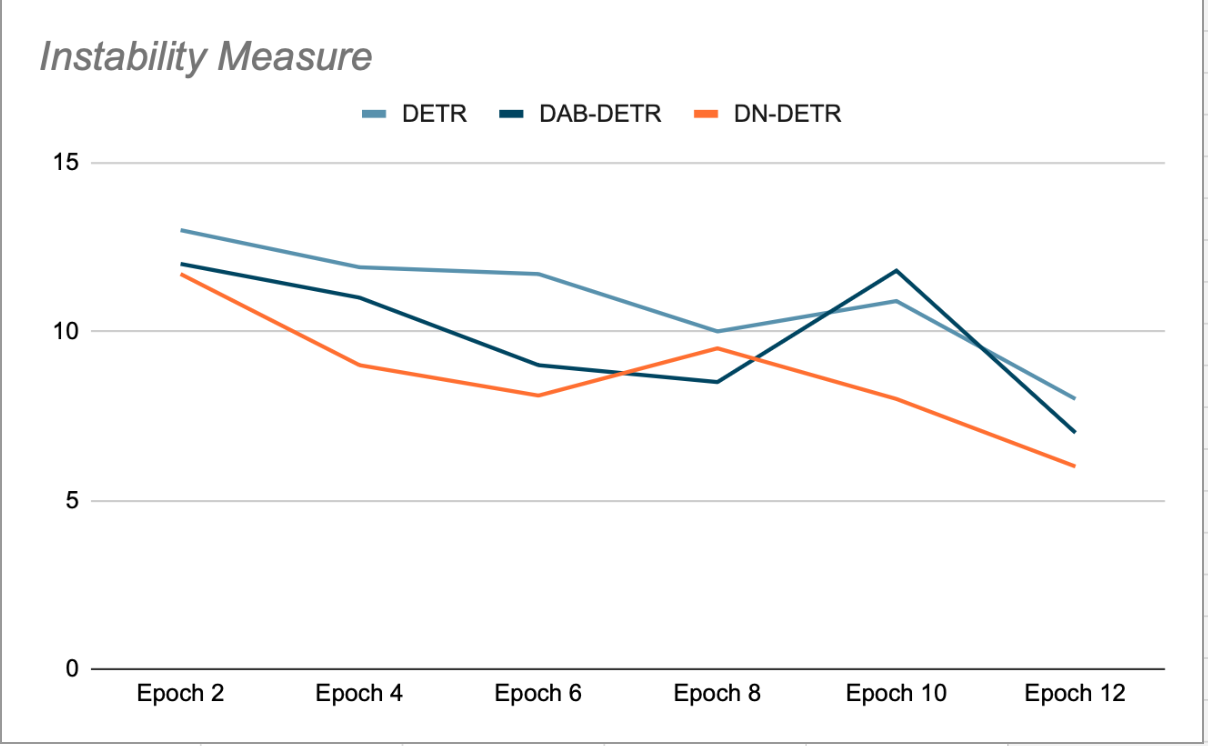
Die Hauptidee von DN-DETR besteht darin, die Ausbildung durch die Schaffung Leicht zu neigende imaginäre DrehpunkteDer Abgleichprozess wird übersprungen. Dies geschieht während des Trainings, indem den GT-Kacheln (True Ground) eine kleine Menge Rauschen hinzugefügt und diese verrauschten Kacheln als Anker für Decoder-Abfragen verwendet werden. DN-Abfragen werden von organischen Abfragen maskiert und umgekehrt, um gegenseitige Aufmerksamkeit zu vermeiden, die das Training beeinträchtigen könnte. Die von diesen Abfragen generierten Erkennungen sind bereits ihren GT-Quellkacheln zugeordnet und erfordern keinen bipartiten Abgleich. Die Autoren von DN-DETR haben gezeigt, dass dies während der Validierungsphasen am Ende jeder Epoche (in denen die Rauschunterdrückung deaktiviert ist) die Modellstabilität im Vergleich zu DETR und DAB-DETR verbessert, d. h., die Plus-Abfragen stimmen in aufeinanderfolgenden Epochen konsistent mit dem GT-Objekt überein (siehe Abbildung 2).
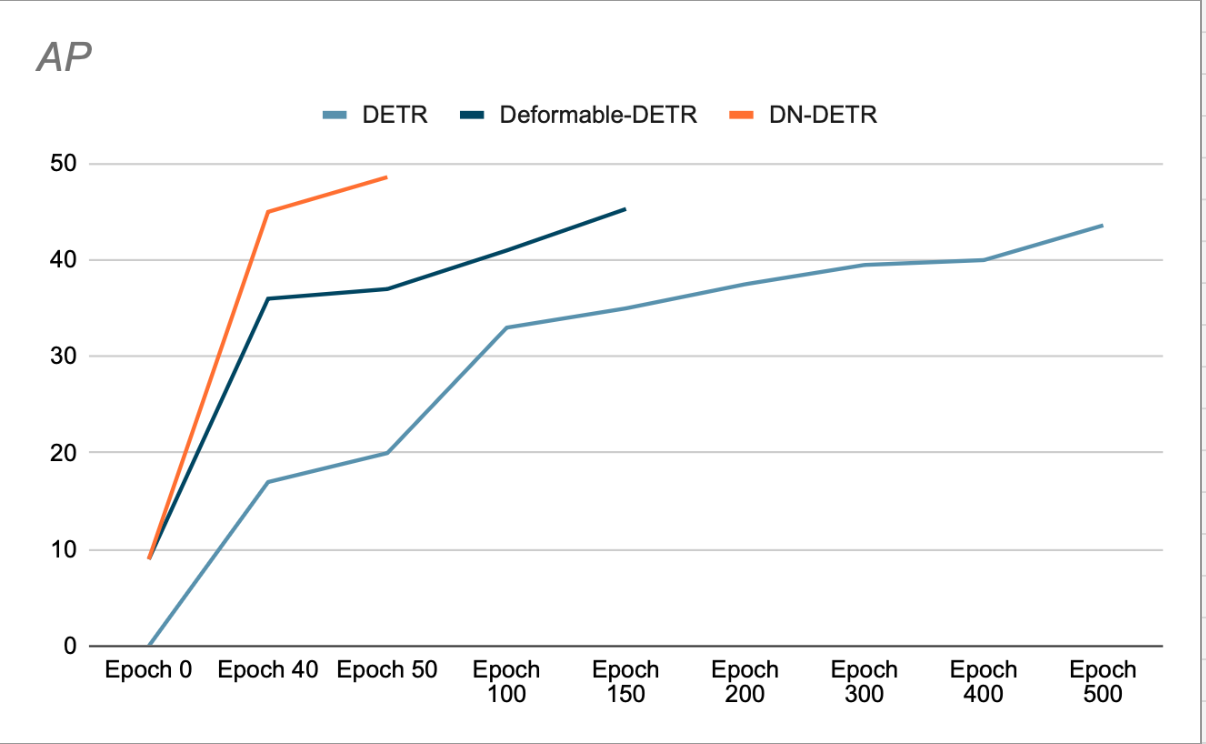
Die Autoren zeigen, dass die Verwendung von DN die Konvergenz beschleunigt und bessere Erkennungsergebnisse erzielt. (Siehe Abbildung 3). Ihre Entfernungsstudie zeigt eine 1.9-prozentige Steigerung der AP (durchschnittliche Genauigkeit) im COCO-Erkennungsdatensatz im Vergleich zum vorherigen SOTA (DAB-DETR, AP 42.2 %), wenn ResNet-50 als Backbone verwendet wird.
DINO und Kontrastrauschentfernung
DINO entwickelte diese Idee weiter und fügte dem Mechanismus zur Rauschunterdrückung kontrastives Lernen hinzu: Zusätzlich zum positiven Beispiel erstellt DINO eine weitere, verrauschte Version jedes GT, die mathematisch so konstruiert ist, dass sie weiter vom GT entfernt ist als das positive Beispiel (siehe Abbildung 4). Diese Version wird als negatives Beispiel für das Training verwendet: Das Modell lernt, die Erkennung zu akzeptieren, die der Grundwahrheit am nächsten kommt, und die Erkennung abzulehnen, die weiter entfernt ist (indem es lernt, die Klasse „kein Objekt“ vorherzusagen).
Darüber hinaus ermöglicht DINO mehrere Clusterings für kontrastives Denoising (CDN) – mehrere verrauschte Anker für jedes GT-Objekt – und holt so das Beste aus jeder Trainingsiteration heraus.
Die DINO-Autoren berichteten von einer durchschnittlichen Genauigkeit (AP) von 49 % (auf COCO val2017) bei Verwendung eines CDN.
Moderne zeitliche Modelle, die Objekte von Frame zu Frame verfolgen müssen, wie etwa Sparse4Dv3, verwenden CDNs und fügen zeitliche Denoising-Gruppen hinzu, in denen einige erfolgreiche DN-Anker (zusammen mit den erlernten Nicht-DN-Ankern) zur Verwendung in nachfolgenden Frames gespeichert werden, was die Leistung des Modells bei der Objektverfolgung verbessert.

Diskussion
Denoising (DN) scheint die Konvergenzgeschwindigkeit und die endgültige Leistung von Vision-Transformer-Detektoren zu verbessern. Bei der Betrachtung der Entwicklung der verschiedenen oben genannten Methoden stellen sich jedoch folgende Fragen:
- DN verbessert Modelle, die lernbare Anker verwenden. Aber sind erlernbare Anker wirklich wichtig? Wird DN auch Modelle verbessern, die nicht erlernbare Anker verwenden?
- Der Hauptbeitrag von DN zum Training besteht darin, dem Gradientenabstiegsprozess Stabilität zu verleihen, indem die bipartite Übereinstimmung umgangen wird. Doch scheint es vor allem deshalb eine binäre Übereinstimmung zu geben, weil es bei der Transformatorarbeit üblich ist, räumliche Einschränkungen bei Abfragen zu vermeiden. Wenn wir also Abfragen manuell auf bestimmte Bildspeicherorte beschränken und auf die binäre Übereinstimmung verzichten (oder eine vereinfachte Version der binären Übereinstimmung verwenden, die für jeden Bildpatch separat ausgeführt wird), werden die Ergebnisse durch DN dennoch verbessert?
Ich konnte keine Werke finden, die klare Antworten auf diese Fragen lieferten. Meine Hypothese ist, dass ein Modell, das nicht lernbare Anker (vorausgesetzt, die Anker sind nicht zu spärlich) und räumlich eingeschränkte Abfragen verwendet, 1 – keinen binären Matching-Algorithmus benötigt und 2 – beim Training nicht von DN profitiert, da die Anker bereits bekannt sind und es keinen Vorteil bringt, die Regression von anderen kurzlebigen Ankern zu lernen.
Wenn die Anker zwar fest, aber verstreut sind, kann ich mir vorstellen, dass die Verwendung flüchtiger Anker den Abstieg erleichtert und einen guten Start in den Trainingsprozess ermöglicht.
Anchor-DETR (Wand et al., 2021) vergleicht die räumliche Verteilung lernbarer und nicht lernbarer Anker und die Leistung der jeweiligen Modelle, und meiner Meinung nach trägt die Lernbarkeit nicht viel zur Modellleistung bei. Es ist erwähnenswert, dass sie in beiden Methoden den ungarischen Algorithmus verwenden. Daher ist unklar, ob sie auf die binäre Übereinstimmung verzichten und trotzdem die Leistung beibehalten könnten.
Zu bedenken ist, dass es möglicherweise produktive Gründe gibt, NMS bei der Inferenz zu vermeiden, was die Verwendung des ungarischen Algorithmus beim Training fördert.
Wo kann die Rauschunterdrückung wirklich wichtig sein? Meiner Meinung nach - in Rückverfolgbarkeit. Beim Tracking wird dem Modell ein Videostream bereitgestellt und es muss nicht nur mehrere Objekte in aufeinanderfolgenden Frames erkennen, sondern auch die eindeutige Identität jedes erkannten Objekts beibehalten. Zeitliche Transformatormodelle, also Modelle, die die sequentielle Natur des Video-Streamings nutzen, verarbeiten einzelne Frames nicht unabhängig voneinander. Stattdessen unterhält es eine Bank, in der frühere Entdeckungen gespeichert werden. Beim Training wird das Tracking-Modell dazu angehalten, von der vorherigen Objekterkennung (oder genauer gesagt vom Fixator, der mit der vorherigen Objekterkennung verknüpft ist) zurückzuschreiten, anstatt einfach vom nächstgelegenen Fixator zurückzuschreiten. Da die vorherige Entdeckung nicht auf ein festes Netzwerk von Stabilisatoren beschränkt ist, ist es plausibel, dass die durch DN angeregte Flexibilität von Vorteil ist. Ich würde sehr gerne zukünftige Werke lesen, die sich mit diesen Themen befassen.
Das ist alles zum Thema Rauschunterdrückung und ihr Beitrag zu Vision Transformers! Wenn Ihnen mein Artikel gefallen hat, sind Sie herzlich eingeladen, einige meiner anderen Artikel über Deep Learning und maschinelles Lernen zu lesen und Computer Vision!
Kommentarfunktion ist geschlossen.