

Erklärung: Wie wählt die L1-Regularisierung automatisch Features aus?
Verstehen Sie den automatischen Merkmalsauswahlprozess, der durch die L1-Regularisierung (LASSO) durchgeführt wird.
Bei der Merkmalsauswahl handelt es sich um den Vorgang, aus einem gegebenen Satz von Merkmalen eine optimale Teilmenge von Merkmalen auszuwählen. Die optimale Teilmenge ist diejenige, die die Leistung des Modells bei der gegebenen Aufgabe maximiert.
Die Merkmalsidentifizierung kann ein manueller Prozess sein oder explizit, wenn sie mit Filtermethoden oder Wrappermethoden. Bei diesen Methoden werden Features iterativ hinzugefügt oder entfernt, basierend auf dem Wert einer festen Metrik, die bestimmt, wie wichtig das Feature für die Vorhersage ist. Bei den Metriken kann es sich um Informationsgewinn, Varianz oder Chi-Quadrat-Statistik handeln. Der Algorithmus trifft unter Berücksichtigung eines festen Schwellenwerts für die Metrik eine Entscheidung zur Annahme/Ablehnung der Funktion. Es ist zu beachten, dass diese Methoden nicht Teil der Modelltrainingsphase sind und davor durchgeführt werden.
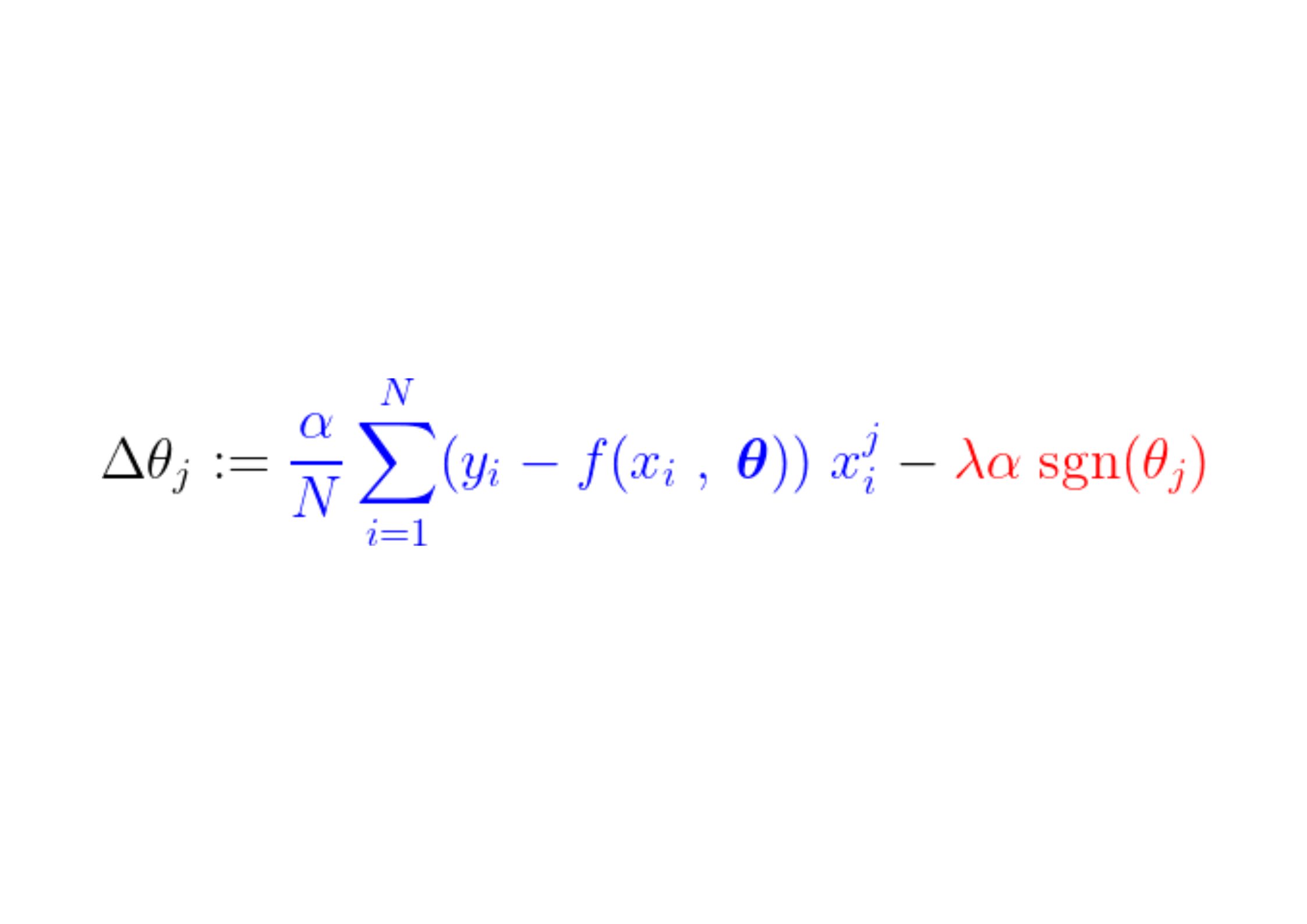
aufstehen Eingebettete Methoden Durch implizite Auswahl von Merkmalen, ohne Verwendung vordefinierter Auswahlkriterien, und Extrahieren dieser aus den Trainingsdaten selbst. Dieser Prozess der Identifizierung wesentlicher Merkmale ist Teil der Modelltrainingsphase. Das Modell lernt, Merkmale zu erkennen und gleichzeitig relevante Vorhersagen zu treffen. In den folgenden Abschnitten beschreiben wir die Rolle der Regularisierung in diesem wesentlichen Merkmalsauswahlprozess und konzentrieren uns dabei auf die L1-Regularisierung und ihre Rolle bei der Verbesserung von Modellen des maschinellen Lernens.
Normalisierung und Modellkomplexität: Erweiterte Strategien zur Leistungsverbesserung
Bei der Regularisierung wird die Modellkomplexität bestraft, um eine Überanpassung zu vermeiden und eine Generalisierung der Aufgabe zu erreichen.
Dabei ist die Komplexität des Modells analog zu seiner Fähigkeit, sich an Muster in den Trainingsdaten anzupassen. Unter der Annahme eines einfachen Polynommodells in 'x„bis zu einem gewissen Grad“d„Je höher die Punktzahl“dBei Polynomen verfügt das Modell über eine größere Flexibilität bei der Erfassung von Mustern in den beobachteten Daten. Diese erhöhte Flexibilität kann dazu führen, dass das Modell die Trainingsdaten auswendig lernt, anstatt die wahren Muster zu erlernen, was seine Fähigkeit zur Verallgemeinerung auf neue Daten verringert.
Overfitting und Underfitting
Beim Versuch, ein Polynommodell mit Grad anzupassen d = 2 Bei einer Reihe von Trainingsbeispielen, die aus einem Polynom dritter Ordnung mit etwas Rauschen stammen, kann das Modell die Stichprobenverteilung nicht angemessen erfassen. Dem Modell fehlt einfach Flexibilität Oder Komplexität Erforderlich für die Modellierung von Daten, die durch Polynome 3. Grades (oder höher) generiert wurden. Dieses Modell soll Unteranpassung Auf Trainingsdaten. Eine Unterladung weist darauf hin, dass das Modell zu einfach ist und die zugrunde liegenden Muster in den Daten nicht erfassen kann.
Wir arbeiten mit demselben Beispiel und gehen nun davon aus, dass wir ein Modell mit einem Grad an d = 6. Mit zunehmender Komplexität sollte es für das Modell nun einfach sein, das ursprüngliche kubische Polynom zu schätzen, das zur Generierung der Daten verwendet wurde (z. B. die Koeffizienten aller Terme mit Exponent > 3 auf 0 setzen). Wenn der Trainingsprozess nicht rechtzeitig abgeschlossen wird, nutzt das Modell weiterhin seine zusätzliche Flexibilität, um den Fehler weiter zu reduzieren und beginnt auch mit der Erfassung verrauschter Proben. Dadurch wird der Trainingsfehler erheblich reduziert, aber das Modell ist jetzt Überanpassungen Auf Trainingsdaten. In realen Umgebungen (oder in der Testphase) ändert sich das Rauschen und alle auf Vorhersagen basierenden Erkenntnisse werden zerstört, was zu hohen Testfehlern führt. Überladung bedeutet, dass das Modell zu komplex ist und Rauschen statt des echten Signals lernt.
Wie bestimmt man die optimale Komplexität des Modells?
In der Praxis verfügen wir häufig nur über ein eingeschränktes oder gar kein Verständnis für den Prozess der Datengenerierung oder die tatsächliche Verteilung der Daten. Das optimale Modell mit der entsprechenden Komplexität zu finden, sodass es weder zu einer Unter- noch zu einer Überanpassung kommt, ist eine große Herausforderung. Dies erfordert den Einsatz effektiver Methoden zur Bewertung der Leistung von Modellen und zur Bestimmung der geeigneten Komplexität, die das beste Gleichgewicht zwischen Genauigkeit und Allgemeingültigkeit erreicht. Durch die Verwendung geeigneter Bewertungsmetriken und -techniken wie der Kreuzvalidierung können Fachleute das Modell ermitteln, das bei unbekannten Daten die beste Leistung erbringt, und so Über- oder Unteranpassungsprobleme vermeiden.
Eine mögliche Technik besteht darin, mit einem ausreichend robusten Modell zu beginnen und dann seine Komplexität durch Merkmalsauswahl zu reduzieren. Je weniger Merkmale, desto weniger komplex ist das Modell.
Wie wir im vorherigen Abschnitt besprochen haben, kann die Merkmalsauswahl explizit (Filtermethoden, Faltungsmethoden) oder implizit erfolgen. Redundante Merkmale, die für die Bestimmung des Werts der Zielvariablen nicht sehr wichtig sind, sollten entfernt werden, um zu vermeiden, dass das Modell darin unkorrelierte Muster lernt. Eine ähnliche Aufgabe wird auch durch die Regularisierung erfüllt. Welchen Zusammenhang gibt es also zwischen Regularisierung und Merkmalsauswahl, wenn es um das Erreichen des gemeinsamen Ziels einer optimalen Modellkomplexität geht? Die Reduzierung der Komplexität in Modellen des maschinellen Lernens ist entscheidend für die Verbesserung der Leistung und die Vermeidung von Überanpassung. Darauf konzentrieren sich sowohl die Regularisierung als auch die Merkmalsauswahl.
L1-Regularisierung als Merkmalsdeterminante
Wir setzen unser Polynommodell fort und stellen es als Funktion f dar, mit den Eingaben xund Transaktionen θ und Grad d،
![]()
Bei einem Polynommodell kann jede Potenz der Eingabe berücksichtigt werden x_i Als Vorteil bietet sich die Bildung eines Vektors folgender Form an:
![]()
Wir definieren auch eine Zielfunktion, deren Minimierung zu den optimalen Parametern führt. * Der Begriff umfasst: Regulierung (Verordnung), die die Modellkomplexität bestraft.
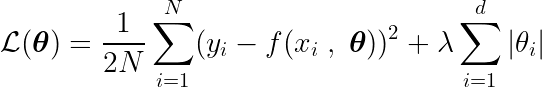
Um das Minimum dieser Funktion zu finden, müssen wir alle kritischen Punkte analysieren, d. h. die Punkte, an denen die Ableitung Null ist oder undefiniert ist.
Die partielle Ableitung kann in Bezug auf einen der Parameter geschrieben werden, θj, folgendermaßen:
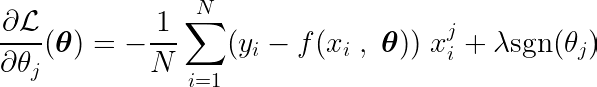
wo die Funktion definiert ist sgn folgendermaßen:
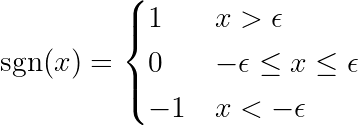
ملاحظةDie Ableitung einer absoluten Funktion unterscheidet sich von der oben definierten Vorzeichenfunktion (sgn). Die ursprüngliche Ableitung ist bei x = 0 undefiniert. Wir erweitern die Definition, um den Wendepunkt bei x = 0 zu entfernen und die Funktion über ihren gesamten Bereich differenzierbar zu machen. Darüber hinaus verwenden Frameworks für maschinelles Lernen (ML) diese erweiterten Funktionen, wenn die zugrunde liegenden Berechnungen die absolute Funktion beinhalten. Schauen Sie sich das an! الرابط Im PyTorch-Forum.
Durch Berechnung der partiellen Ableitung der Zielfunktion nach einem einzelnen Koeffizienten θj, und wenn wir es mit Null gleichsetzen, können wir eine Gleichung konstruieren, die den optimalen Wert von θj Mit Prognosen, Zielen und Features.
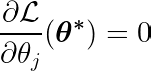
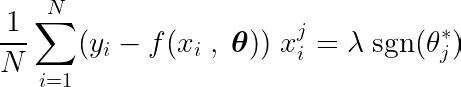
Lassen Sie uns die obige Gleichung untersuchen. Unter der Annahme, dass die Eingaben und Ziele um den Mittelwert zentriert waren (d. h., die Daten wurden im Vorverarbeitungsschritt standardisiert), stellt der Term auf der linken Seite (LHS) effektiv dar Varianz Zwischen Merkmalsnummer j und der Differenz zwischen den erwarteten und Zielwerten.
Die statistische Kovarianz zwischen zwei Variablen bestimmt den Einfluss, den eine Variable auf den Wert der zweiten Variable hat (und umgekehrt).
Die Vorzeichenfunktion auf der rechten Seite zwingt die Variation auf der linken Seite, nur drei Werte anzunehmen (da die Vorzeichenfunktion nur -1, 0 und 1 zurückgibt). Wenn die Funktion j Unnötig und beeinflusst die Vorhersagen nicht, die Varianz wird nahe Null liegen, wodurch der entsprechende Koeffizient θj* Null. Dies führt dazu, dass das Feature aus dem Modell entfernt wird. Dieser Prozess trägt dazu bei, die Komplexität zu reduzieren und die Modellleistung zu verbessern.
Stellen Sie sich die Funktion des Zeichens als eine vom Wasser geformte Rille vor. Sie können in die Schlucht (also das Flussbett) hineingehen, aber um wieder herauszukommen, müssen Sie auf riesige Hindernisse oder steile Stromschnellen stoßen. Die L1-Regularisierung erzeugt einen „Schwellenwert“-Effekt, der dem Gradienten der Verlustfunktion ähnelt. Der Gradient muss stark genug sein, um die Barrieren zu durchbrechen oder Null zu werden, sodass der Koeffizientenwert schließlich Null wird.
Um ein realistischeres Beispiel zu liefern, betrachten Sie einen Datensatz, der Stichproben enthält, die aus einer geraden Linie (zweifaktoriell parametrisiert) mit etwas zusätzlichem Rauschen abgeleitet wurden. Das optimale Modell sollte nicht mehr als zwei Parameter haben, da es sonst zu einer Überanpassung an das Rauschen in den Daten kommt (mit der zusätzlichen Freiheit/Leistung des Polynoms). Das Ändern der höheren Leistungskoeffizienten in einem Polynommodell wirkt sich nicht auf den Unterschied zwischen den Zielen und den Modellvorhersagen aus und verringert somit deren Varianz mit dem Merkmal.
Während des Trainingsprozesses wird ein fester Schritt zum Gradienten der Verlustfunktion hinzugefügt/abgezogen. Wenn der Gradient der Verlustfunktion (MSE – mittlerer quadratischer Fehler) kleiner als die konstante Schrittweite ist, erreicht der Koeffizient schließlich den Wert 0. Beachten Sie die folgende Gleichung, die zeigt, wie die Koeffizienten mithilfe des Gradientenabstiegs aktualisiert werden:

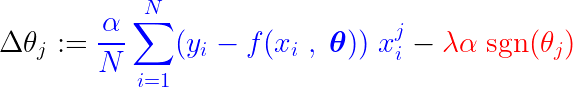
Wenn der blaue Teil oben kleiner ist als la, was an sich eine sehr kleine Zahl ist, dann Δθj Es ist fast ein stetiger Schritt. la. Das Signal für diesen Schritt (roter Teil) hängt ab von: sgn(θj), dessen Ausgabe abhängt von θj. Wenn der Wert θj Positiv, d.h. größer als ε, das sgn(θj) gleich 1, also Δθj Ungefähr gleich -laund drückt es in Richtung Null.
Um den konstanten Schritt (roter Teil) zu unterdrücken, der den Koeffizienten auf Null setzt, muss der Gradient der Verlustfunktion (blauer Teil) größer als die Schrittweite sein. Um einen größeren Gradienten für die Verlustfunktion zu erhalten, sollte der Merkmalswert die Modellausgabe erheblich beeinflussen.
Auf diese Weise wird das Merkmal oder genauer gesagt der entsprechende Parameter, dessen Wert nicht mit der Modellausgabe zusammenhängt, während des Trainings durch die L1-Regularisierung auf Null gesetzt.
Weiterführende Literatur und Fazit
- Um mehr Einblicke in dieses Thema zu erhalten, habe ich eine Frage auf dem Reddit r/MachineLearning gepostet, undNachverfolgen Es enthält verschiedene Interpretationen, die Sie vielleicht lesen möchten.
- Madiyar Aitbayev hat auch interessanter Blog Behandelt dieselbe Frage, jedoch mit einer technischen Erklärung.
- Blog Brian King erklärt Organisation aus einer probabilistischen Perspektive.
- Dies Diskussion Auf der CrossValidated-Website erklärt er, warum das L1-Kriterium spärliche Modelle fördert. Blog In einem ausführlichen Artikel von Mukul Ranjan wird erklärt, warum die L1-Norm dazu ermutigt, Transaktionen auf Null zu reduzieren, die L2-Norm jedoch nicht.
„L1-Regularisierung wählt Features aus“ ist eine einfache Aussage, der die meisten ML-Lernenden zustimmen, ohne auf die interne Funktionsweise einzugehen. In diesem Blog versuche ich, den Lesern mein Verständnis und mein mentales Modell vorzustellen, um die Frage auf intuitive Weise zu beantworten. Für Vorschläge und Zweifel finden Sie meine E-Mail unter Meine Website. Lernen Sie weiter und haben Sie einen wunderschönen Tag!
Kommentarfunktion ist geschlossen.