

Warum die meisten Cybersicherheitsrisikomodelle scheitern, bevor sie überhaupt funktionieren
Die Notwendigkeit quantitativer Überlegungen zu Cybersicherheitsrisiken
Führungskräfte im Bereich Cybersicherheit stehen vor unmöglichen Fragen. „Wie hoch ist die Wahrscheinlichkeit einer Sicherheitsverletzung in diesem Jahr?“ und "Wie viel wird es kosten?" und „Wie viel sollten wir ausgeben, um es zu stoppen?“
Die meisten heute verwendeten Risikomodelle basieren jedoch immer noch auf Vermutungen, Instinkt und farbcodierten Risikokarten und nicht auf Daten.
Tatsächlich fand ich PwCs Studie „Global Digital Trust Insights 2025“ Nur 15 % der Organisationen nutzen quantitative Risikomodelle in nennenswertem Umfang.
In diesem Artikel wird untersucht, warum herkömmliche Risikomodelle für die Cybersicherheit nicht ausreichen und wie die Anwendung einfacher statistischer Tools wie der Wahrscheinlichkeitsmodellierung eine bessere Lösung bietet.

Zwei Hauptrichtungen der Cyber-Risikomodellierung
Cyber-Risikomodelle sind: Systematische Rahmen oder Methoden zur Analyse, Bewertung und Messung von Cybersicherheitsbedrohungen und deren potenziellen Auswirkungen auf Informationssysteme, Daten oder Unternehmen.
Fachleute für Informationssicherheit verwenden im Rahmen des Risikobewertungsprozesses hauptsächlich zwei verschiedene Methoden zur Risikomodellierung: qualitative und quantitative. Es wird berücksichtigt Quantitative Modellierung von Cyberrisiken Eine fortgeschrittene Technik, die spezielle Fachkenntnisse erfordert.
Qualitative Modelle zur Risikobewertung
Stellen Sie sich zwei Teams vor, die dasselbe Risiko bewerten. Man gibt dem Risiko eine Punktzahl von 4/5 für die Wahrscheinlichkeit und 5/5 für die Auswirkung. Das andere Team gibt ihr 3/5 und 4/5. Beide Teams lokalisieren es auf einer Matrix. Doch keiner von beiden kann die Frage des CFO beantworten: „Wie wahrscheinlich ist es, dass dies tatsächlich passiert, und was wird es uns kosten?“
Der qualitative Ansatz basiert auf einer subjektiven Risikobewertung und beruht hauptsächlich auf der Intuition des Bewerters. Bei einem qualitativen Ansatz werden im Allgemeinen die Wahrscheinlichkeit und die Auswirkungen von Risiken auf einer Ordinalskala, beispielsweise von 1 bis 5, bewertet.
Als Nächstes werden die Risiken in der Risikomatrix lokalisiert, um zu verstehen, wo sie auf dieser Ordinalskala einzuordnen sind.
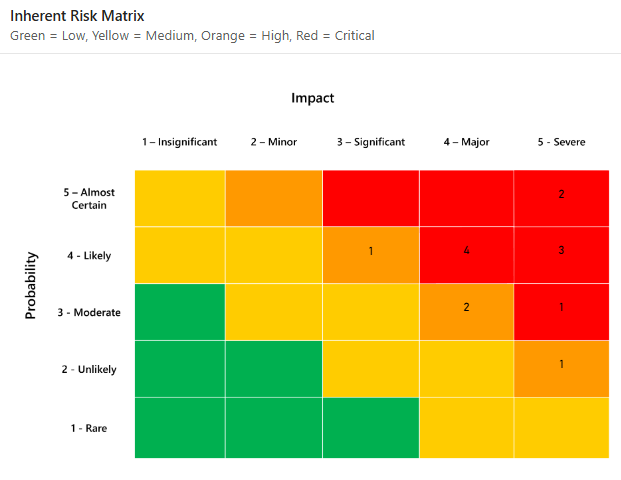
Die beiden Ordinalskalen werden häufig miteinander multipliziert, um die größten Risiken anhand ihrer Wahrscheinlichkeit und Auswirkung zu priorisieren. Auf den ersten Blick erscheint dies sinnvoll, da die allgemein verwendete Definition von Risiko in der Informationssicherheit wie folgt lautet:
[text{Risiko} = text{Wahrscheinlichkeit} mal text{Auswirkung}]
Aus statistischer Sicht birgt die qualitative Risikomodellierung jedoch einige sehr erhebliche Risiken.
Das erste dieser Risiken ist die Verwendung von Ordinalskalen. Während die Zuordnung von Zahlen zur Ordinalskala den Anschein einer mathematischen Unterstützung des Modells erweckt, ist dies lediglich eine Illusion.
Ordinalskalen sind lediglich Beschriftungen – es gibt keinen definierten Abstand zwischen ihnen. Der Abstand zwischen einem Risiko mit der Auswirkung „2“ und einem Risiko mit der Auswirkung „3“ ist nicht quantifizierbar. Das Ändern der Beschriftungen auf der Ordinalskala in „A“, „B“, „C“, „D“ und „E“ macht keinen Unterschied.
Dies wiederum bedeutet, dass unsere Risikoformulierung bei der Verwendung qualitativer Modelle fehlerhaft ist. Es ist unmöglich, die Wahrscheinlichkeit von „B“ multipliziert mit der Wirkung von „C“ zu berechnen.
Eine weitere große Falle ist die Modellunsicherheit. Wenn wir Cyberrisiken modellieren, modellieren wir unsichere zukünftige Ereignisse. Tatsächlich kann es zu einer Reihe von Ergebnissen kommen.
Die Reduzierung des Cyberrisikos auf Einzelpunktschätzungen (wie etwa „20/25“ oder „Hoch“) berücksichtigt nicht den wichtigen Unterschied zwischen „der wahrscheinlichste jährliche Verlust beträgt 1 Million US-Dollar“ und „es besteht eine 5-prozentige Chance für einen Verlust von 10 Millionen US-Dollar oder mehr“.
Quantitative Risikomodellierung: Erweiterte Analyse
Stellen Sie sich ein Team vor, das eine Risikobewertung durchführt. Sie schätzen die Ergebnisse auf eine Spanne von 100 bis 10 Millionen Dollar. Durch die Durchführung einer Monte-Carlo-Simulation ermitteln sie eine 10-prozentige Chance auf jährliche Verluste von über 480 Million US-Dollar und einen erwarteten Verlust von XNUMX US-Dollar. Wenn der CFO nun fragt: „Wie wahrscheinlich ist das und was wird es kosten?“Das Team kann mit Daten reagieren, nicht nur mit Intuition.
Dieser Ansatz verlagert die Diskussion von vagen Risikoklassifizierungen hin zu Möglichkeiten und potenzielle finanzielle Auswirkungen, eine Sprache, die Führungskräfte verstehen.
Wenn Sie über einen statistischen Hintergrund verfügen, sollte Ihnen hier ein Konzept besonders auffallen:
Wahrscheinlichkeit.
Bei der Modellierung von Cybersicherheitsrisiken handelt es sich im Kern um den Versuch, die Wahrscheinlichkeit des Eintretens bestimmter Ereignisse und die Auswirkungen ihres Eintretens zu quantifizieren. Dies öffnet die Tür für eine Vielzahl statistischer Werkzeuge, wie etwa die Monte-Carlo-Simulation, mit der sich Unsicherheiten wesentlich effektiver modellieren lassen als mit ordinalen Maßen.
Bei der quantitativen Risikomodellierung werden statistische Modelle verwendet, um Verlusten Dollarwerte zuzuweisen und die Wahrscheinlichkeit des Eintretens dieser Verlustereignisse zu modellieren, wodurch zukünftige Unsicherheiten erfasst werden.
Während eine qualitative Analyse manchmal das wahrscheinlichste Ergebnis abschätzen kann, erfasst sie nicht das gesamte Spektrum an Unsicherheiten, wie etwa seltene, aber schwerwiegende Ereignisse, die als „Long-Tail-Risiken“ bezeichnet werden.
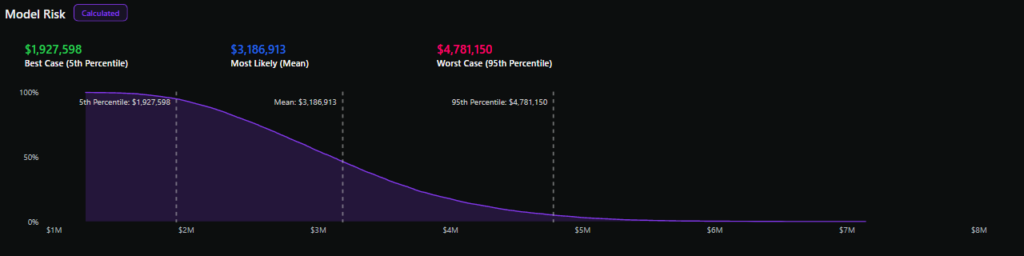
Die Verlustüberschreitungskurve stellt die Wahrscheinlichkeit dar, dass ein bestimmter jährlicher Verlustbetrag auf der Y-Achse überschritten wird, und unterschiedliche Verlustbeträge auf der X-Achse, woraus sich eine abfallende Linie ergibt.
Durch das Ziehen verschiedener Prozentsätze aus der Verlustüberschusskurve, beispielsweise des 90. Perzentils, des Medians und des XNUMX. Perzentils, kann mit XNUMX-prozentiger Sicherheit eine Vorstellung von den potenziellen jährlichen Verlusten für ein Risiko gewonnen werden.
Während eine Einpunktschätzung der qualitativen Analyse die wahrscheinlichsten Risiken abschätzen kann (abhängig von der Genauigkeit der Beurteilung durch die Gutachter), erfasst die quantitative Analyse die Ergebnisunsicherheit, selbst wenn sie selten, aber dennoch möglich ist (bekannt als „Long-Tail-Risiko“).
Über das Cyberrisiko hinausblicken: Risikomodelle in der Cybersicherheit verbessern
Um unsere Risikomodelle im Bereich Informationssicherheit zu verbessern, müssen wir nur einen Blick nach außen werfen, insbesondere auf die Technologien, die in anderen Bereichen eingesetzt werden. Risikomodelle haben sich in zahlreichen Anwendungsbereichen, beispielsweise im Finanz- und Versicherungswesen, in der Flugsicherheit und im Lieferkettenmanagement, erheblich weiterentwickelt. Diese Bereiche liefern wertvolle Erkenntnisse, die auf die Cybersicherheit angewendet werden können.
Finanzteams nutzen Modelle zur Verwaltung des Anlageportfoliorisikos unter Verwendung ähnlicher Bayes-Statistiken. Während Versicherungsteams Risiken mithilfe ausgefeilter versicherungsmathematischer Modelle modellieren. Die Luftfahrtindustrie modelliert das Risiko von Systemausfällen mithilfe von Wahrscheinlichkeitsmodellen. Supply-Chain-Management-Teams modellieren Risiken mithilfe einer probabilistischen Simulation. Diese Methoden bieten eine solide Grundlage für die Entwicklung effektiver Cyber-Risikomodelle.
Die Werkzeuge sind bereits vorhanden. Die mathematischen Grundlagen sind gut verstanden. Andere Branchen haben den Weg geebnet. Jetzt ist es an der Zeit, dass die Cybersicherheit quantitative Risikomodelle einbezieht, um bessere und fundiertere Entscheidungen zu treffen, die zu verbesserten Cybersicherheitsstrategien und geringeren potenziellen Verlusten führen. Die Einführung dieser quantitativen Modelle stellt einen entscheidenden Schritt hin zu einem wirksameren Cyber-Risikomanagement dar.
خلاصة الرئيسية
| Al-Baqara | Al-Kaida |
| Ordinalskalen (1-5) | Probabilistische Modellierung |
| persönliche Intuition | statistische Genauigkeit |
| Einzelne Bewertungspunkte | Risikoverteilungen |
| Heatmaps und Farbcodes | Verlustüberschreitungskurven |
| Ignoriert seltene, aber schwerwiegende Ereignisse | Erfasst Long-Tail-Risiken |
Kommentarfunktion ist geschlossen.