

Leistungsbewertung von DeepSeek-R1-destillierten Modellen auf GPQA mit Ollama und Simple-Evals von OpenAI
Richten Sie den GPQA-Diamond-Benchmark ein und führen Sie ihn auf lokal destillierten DeepSeek-R1-Modellen aus, um deren Inferenzfähigkeiten zu bewerten.
Neueste Modellvorstellung DeepSeek-R1 Große Resonanz in der globalen KI-Community. Es wurden Durchbrüche erzielt, die mit Inferenzmodellen von Meta und OpenAI vergleichbar sind, und dies in einem Bruchteil der Zeit und zu wesentlich geringeren Kosten.
Doch wie können wir jenseits der Schlagzeilen und des Online-Hypes die Inferenzfähigkeiten eines Modells anhand anerkannter Kriterien bewerten? Dies ist eine wichtige Frage für KI-Experten.
. Benutzeroberfläche Tiefensuche Dadurch lassen sich die Funktionen leicht erkunden, die programmgesteuerte Verwendung bietet jedoch tiefere Einblicke und eine reibungslosere Integration in reale Anwendungen. Wenn man versteht, wie diese Modelle lokal funktionieren, ermöglicht man auch eine bessere Kontrolle und einen besseren Offline-Zugriff.

In diesem Artikel erfahren Sie, wie Sie Ollama Und einfache Auswertungen von OpenAI Um die Inferenzfähigkeiten der destillierten DeepSeek-R1-Modelle basierend auf dem Benchmark zu bewerten GPQA-Diamant Dieses Kriterium gilt als eines der wichtigsten Instrumente zur Bewertung von Modellen künstlicher Intelligenz im Bereich des logischen Denkens.
Für dich Link zum GitHub-Repository Begleitend zu diesem Artikel.
(1) Was sind die Modelle des Denkens?
Inferenzmodelle wie DeepSeek-R1 und die O-Serienmodelle von OpenAI (z. B. o1, o3) sind große Sprachmodelle (LLMs), die mithilfe von bestärkendem Lernen trainiert werden, um Inferenzen durchzuführen. Diese Modelle sind fortschrittliche Werkzeuge auf dem Gebiet der künstlichen Intelligenz und stellen den Höhepunkt der Entwicklung der Fähigkeit von Maschinen dar, logisch zu denken und komplexe Probleme zu lösen.
Heuristiken zeichnen sich dadurch aus, dass vor der Antwort gründlich nachgedacht wird und eine lange Reihe innerer Gedanken vor der Antwort entsteht. Es eignet sich hervorragend zum Lösen komplexer Probleme, zum Programmieren, zum wissenschaftlichen Denken und zur mehrstufigen Planung von Agenten-Workflows. Diese Fähigkeiten machen sie in Bereichen wie der fortgeschrittenen Softwareentwicklung, der wissenschaftlichen Forschung und der komplexen Prozessautomatisierung unverzichtbar.
(2) Was ist das DeepSeek-R1-Modell?
DeepSeek-R1 ist ein hochmodernes Open-Source-Large Language Model (LLM), das speziell für Fortgeschrittenes Denken. Eingereicht im Januar 2025 im Forschungspapier "DeepSeek-R1: Steigerung der Inferenzleistung in großen Sprachmodellen durch bestärkendes Lernen". DeepSeek-R1 ist ein Pioniermodell auf dem Gebiet der künstlichen Intelligenz.
Dieses Modell basiert auf einer Large Language Model (LLM)-Architektur mit 671 Milliarden Parametern und wurde mithilfe von umfangreichem Reinforcement Learning (RL) basierend auf dem folgenden Pfad trainiert:
- Zwei Erweiterungsphasen zielen darauf ab, verbesserte Denkmuster zu entdecken und sich an menschlichen Vorlieben auszurichten.
- Zwei Phasen der überwachten Feinabstimmung dienen als Ausgangspunkt für die Inferenz- und Nicht-Inferenzfähigkeiten des Modells.
Zur Veranschaulichung hat DeepSeek zwei Modelle trainiert:
- Das erste Modell, DeepSeek-R1-Zeroist ein Inferenzmodell, das mithilfe von Reinforcement Learning trainiert wurde und Daten zum Trainieren des zweiten Modells generiert. DeepSeek-R1.
- Dies wird durch die Erstellung von Inferenzspuren erreicht, von denen basierend auf ihren Endergebnissen nur qualitativ hochwertige Ausgaben beibehalten werden.
- Dies bedeutet, dass die Beispiele für das bestärkende Lernen (RL) in dieser Trainingspipeline im Gegensatz zu den meisten Modellen nicht von Menschen kuratiert, sondern vom Modell selbst generiert werden.
Das Ergebnis ist, dass das Modell eine ähnliche Leistung erzielte wie führende Modelle wie OpenAIs o1-Modell Bei Aufgaben wie Mathematik, Programmieren und komplexem Denken.
(3) Verständnis des Destillationsprozesses und der destillierten Modelle von DeepSeek-R1
Zusätzlich zum vollständigen Modell haben sie auch sechs kleinere dichte Modelle (auch DeepSeek-R1 genannt) in verschiedenen Größen (1.5B, 7B, 8B, 14B, 32B, 70B) als Open Source bereitgestellt, die aus DeepSeek-R1 destilliert wurden und auf Qwen Oder Lama Als Basismodell.
Destillation Es handelt sich um eine Technik, bei der ein kleineres Modell („Schüler“) trainiert wird, um die Leistung eines größeren, leistungsfähigeren Modells zu replizieren, das zuvor trainiert wurde („Lehrer“).
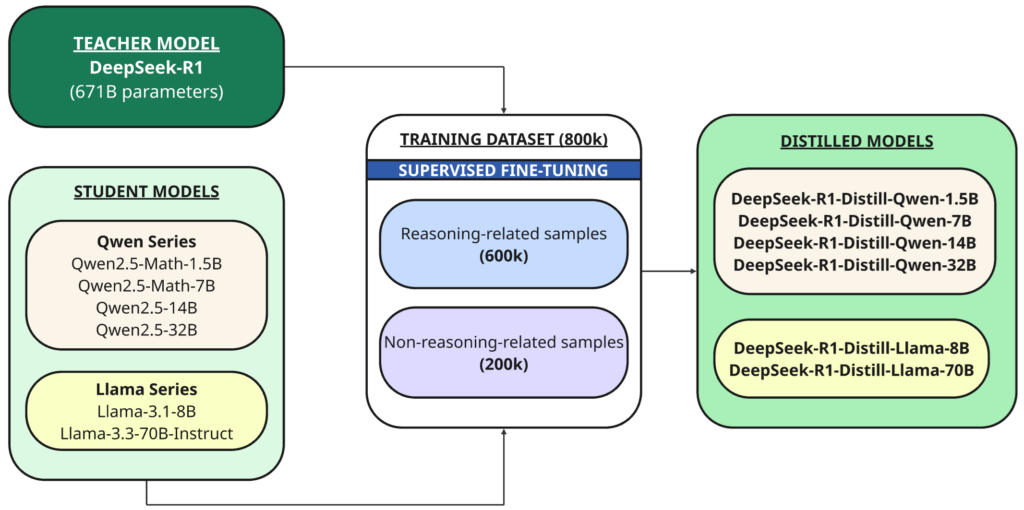
In diesem Fall ist der Lehrer das 1B DeepSeek-R671-Modell und die Schüler sind die sechs Modelle, die mithilfe dieses Open-Source-Basismodells destilliert wurden:
- Qwen2.5 – Mathe-1.5B
- Qwen2.5 – Mathe-7B
- Qwen2.5 – 14B
- Qwen2.5 – 32B
- Lama-3.1 – 8B
- Lama-3.3 — 70B-Anweisung
DeepSeek-R1 wurde als Lehrermodell verwendet, um 800,000 Trainingsbeispiele zu generieren, eine Mischung aus Inferenz- und Nicht-Inferenzbeispielen, für die Destillation durch überwachte Feinabstimmung Für Basismodelle (1.5B, 7B, 8B, 14B, 32B und 70B).
Warum also destillieren wir überhaupt?
Ziel ist es, die Inferenzfähigkeiten größerer Modelle wie DeepSeek-R1 671B auf kleinere, effizientere Modelle zu übertragen. Dadurch können kleinere Modelle komplexe Inferenzaufgaben schneller und ressourcenschonender bewältigen.
Darüber hinaus verfügt DeepSeek-R1 über eine enorme Anzahl von Parametern (671 Milliarden), was die Ausführung auf den meisten Verbrauchergeräten erschwert.
Selbst das leistungsstärkste MacBook Pro mit einem maximalen gemeinsamen Speicher von 128 GB reicht nicht aus, um ein Modell mit Parametern von 671 Milliarden auszuführen.
Destillierte Modelle eröffnen daher die Möglichkeit, sie auf Geräten mit begrenzten Rechenressourcen einzusetzen.
erreicht Unfault Eine bemerkenswerte Leistung durch die Quantisierung des ursprünglichen DeepSeek-R1-Modells mit 671 Milliarden Parametern auf nur 131 GB – eine bemerkenswerte Größenreduzierung um 80 %. Allerdings bleibt die Anforderung von 131 GB VRAM ein erhebliches Hindernis, insbesondere für Entwickler, die an Geräten mit begrenzten Ressourcen arbeiten. Dieser Erfolg stellt einen bedeutenden Schritt dar, um große KI-Modelle einem breiteren Benutzerkreis zugänglich zu machen.
(4) Auswahl des optimalen destillierten Modells
Es stehen sechs verschiedene Größen destillierter Modelle zur Auswahl. Die Wahl des richtigen Modells hängt weitgehend von den Fähigkeiten Ihrer lokalen Ausrüstung ab.
Für diejenigen mit Hochleistungs-GPUs oder -CPUs, die maximale Leistung benötigen, sind die größeren DeepSeek-R1-Modelle (32B und höher) ideal – sogar die Quantum 671B-Version ist brauchbar.
Wenn die Ressourcen jedoch begrenzt sind oder Sie (wie ich) schnellere Build-Zeiten bevorzugen, sind kleinere destillierte Varianten wie 8B oder 14B eine bessere Option. Dadurch werden Leistung und Ressourcenbedarf ausgeglichen.
Für dieses Projekt verwende ich das destillierte DeepSeek-R1-Modell. Qwen-14B, was den von Ihnen festgestellten Hardwareeinschränkungen entspricht. Dieses Modell (14B) stellt einen hervorragenden Kompromiss zwischen Genauigkeit und Geschwindigkeit dar und passt daher perfekt zu meiner Entwicklungsumgebung.
(5) Kriterien zur Bewertung der Inferenzfähigkeit großer Sprachmodelle
Große Sprachmodelle (LLMs) werden normalerweise mithilfe standardisierter Metriken bewertet, die ihre Leistung bei verschiedenen Aufgaben bestimmen, darunter Sprachverständnis, Codegenerierung, Befolgen von Anweisungen und Beantworten von Fragen. Gängige Beispiele sind Kennzahlen wie: MMLU, Und HumanEval, Und MGSM. Diese Metriken sind für die Bewertung der Fähigkeiten großer Sprachmodelle von entscheidender Bedeutung.
Um die Fähigkeit eines großen Sprachmodells zum logischen Denken zu messen, benötigen wir anspruchsvollere Benchmarks, die sich stark auf das logische Denken konzentrieren und über oberflächliche Aufgaben hinausgehen. Hier sind einige gängige Beispiele, die sich auf die Beurteilung fortgeschrittener Denkfähigkeiten konzentrieren:
(i) AIME 2024-Prüfung: Wettbewerbsmathematik
- Bereiten Amerikanische Einladungsprüfung für Mathematik (AIME) 2024 Ein robuster Benchmark zur Bewertung der Fähigkeiten großer Sprachmodelle (LLMs) im mathematischen Denken.
- Diese Prüfung stellt eine erhebliche Herausforderung im Mathematikwettbewerb dar, da sie komplexe, mehrstufige Probleme enthält. Die Prüfung testet die Fähigkeit großer Sprachmodelle, komplexe Fragen zu verstehen, fortgeschrittenes Denken anzuwenden und präzise symbolische Manipulationen durchzuführen. Der AIME ist ein wichtiges Maß zur Beurteilung komplexer mathematischer Problemlösungsfähigkeiten.
(ii) Codeforces – Wettbewerbskodex
- aufstehen Codeforces Standard Bewertung der Inferenzfähigkeit eines großen Sprachmodells (LLM) anhand realer wettbewerbsorientierter Programmierprobleme von Codeforces, einer für algorithmische Herausforderungen bekannten Plattform. Codeforces ist der Goldstandard für die Bewertung der Fähigkeiten von KI-Modellen zur Lösung komplexer Probleme.
- Diese Probleme testen die Fähigkeit eines großen Sprachmodells (LLM), komplexe Anweisungen zu verstehen, logische und mathematische Schlussfolgerungen zu ziehen, mehrstufige Lösungen zu planen und korrekten und effizienten Code zu generieren. Diese Probleme erfordern ein tiefes Verständnis von Algorithmen und Datenstrukturen sowie die Fähigkeit, das Problem in ausführbaren Code zu übersetzen.
(iii) GPQA Diamond – wissenschaftliche Fragen auf PhD-Niveau
- GPQA-Diamond ist eine ausgewählte Teilmenge von Die schwierigsten Fragen Vom Standard GPQA (Fragen und Antworten zum Aufbaustudium Physik) Das umfassendste und speziell dafür konzipierte Modul, die Grenzen der Schlussfolgerungsfähigkeit von LLM-Modellen bei fortgeschrittenen Themen auf PhD-Niveau zu erweitern. Dieser Standard stellt eine echte Herausforderung für die Fähigkeit der KI dar, komplexe wissenschaftliche Konzepte zu verstehen und abzuleiten.
- Während GPQA eine Reihe konzeptioneller und berechnungsbasierter Fragen für Postgraduierte enthält, isoliert GPQA-Diamond nur die schwierigsten Fragen und jene, die intensives Denken erfordern.
- Dieses Kriterium gilt als „Google-resistent“, das heißt, es ist selbst bei uneingeschränktem Webzugriff schwer zu beantworten. Dies macht es zu einem wertvollen Werkzeug zur Beurteilung der Fähigkeit großer Sprachmodelle, unabhängig zu denken.
- Hier ist ein Beispiel für eine GPQA-Diamond-Frage:
### GPQA Diamond – Beispielfrage (Molekularbiologie) Eine eukaryotische Zelle hat einen Mechanismus entwickelt, um makromolekulare Bausteine in Energie umzuwandeln. Der Prozess findet in den Mitochondrien statt, den Energiefabriken der Zellen. In einer Reihe von Redoxreaktionen wird die Energie aus der Nahrung zwischen den Phosphatgruppen gespeichert und als universelle Zellwährung verwendet. Die energiegeladenen Moleküle werden aus dem Mitochondrium heraustransportiert, um in allen zellulären Prozessen zum Einsatz zu kommen. Sie haben ein neues Medikament gegen Diabetes entdeckt und möchten untersuchen, ob es eine Wirkung auf die Mitochondrien hat. Sie haben eine Reihe von Experimenten mit Ihrer HEK293-Zelllinie durchgeführt. Welches der unten aufgeführten Experimente hilft Ihnen nicht dabei, die mitochondriale Rolle Ihres Medikaments zu entdecken: (A) Extraktion der Mitochondrien durch differentielle Zentrifugation, gefolgt vom Glucose Uptake Colorimetric Assay Kit (B) Durchflusszytometrie nach Markierung mit 2.5 µM 5,5',6,6'-Tetrachloro-1,1',3,3'-tetraethylbenzimidazolylcarbocyanine Iodid (C) Transformation von Zellen mit rekombinanter Luciferase und Luminometermessung nach Zugabe von 5 µM Luciferin zum Überstand (D) Konfokale Fluoreszenzmikroskopie nach Mito-RTP-Färbung der Zellen
In diesem Projekt Als Standard für die Schlussfolgerung verwenden wir GPQA-Diamond., wie ich es verwendet habe OpenAI Und DeepSeek Um ihre Inferenzmodelle zu bewerten. Die Wahl von GPQA-Diamond als Bewertungsstandard ist ein Beweis für dessen Schwierigkeit und Bedeutung im Bereich der KI-Entwicklung.
(6) Eingesetzte Tools
In diesem Projekt verwenden wir hauptsächlich Ollama Und einfache Auswertungen Von OpenAI. Ollama ist eine leistungsstarke Plattform zum lokalen Ausführen großer Sprachmodelle, während simple-evals ein Framework zum Bewerten der Leistung dieser Modelle bietet.
(i) Ollama
Ollama Es handelt sich um ein Open-Source-Tool, das die Ausführung großer Sprachmodelle (LLMs) auf unserem Computer oder einem lokalen Server vereinfacht. Olama ist eine ideale Plattform für die lokale Ausführung von KI-Modellen.
Es fungiert als Manager und Laufzeit und übernimmt Aufgaben wie Downloads und Umgebungseinrichtung. Dadurch können Benutzer mit diesen Modellen interagieren, ohne dass eine ständige Internetverbindung erforderlich ist oder sie auf Cloud-Dienste angewiesen sind. Die Verwaltung lokaler großer Sprachmodelle (LLMs) ist eine Kernfunktion von Olama.
Es unterstützt viele große Open-Source-Sprachmodelle, einschließlich DeepSeek-R1, und ist plattformübergreifend mit macOS, Windows und Linux kompatibel. Darüber hinaus bietet es eine unkomplizierte Einrichtung mit minimalem Aufwand und effizienter Ressourcennutzung. Mit Ollama können Sie die Leistung künstlicher Intelligenz direkt auf Ihrem Gerät nutzen.
WichtigStellen Sie sicher, dass Ihr lokaler Computer über Folgendes verfügt: GPU-Zugänglichkeit Für Ollama beschleunigt dies die Leistung erheblich und macht das nachfolgende Benchmarking im Vergleich zur CPU effizienter. Führen Sie den Befehl aus
nvidia-smiÜberprüfen Sie im Terminal, ob die GPU erkannt wird. Dieses Verfahren stellt sicher, dass die Fähigkeiten des Geräts maximiert werden, um Modelle mit hoher Effizienz auszuführen.
(ii) OpenAI simple-evals-Bibliothek zur Bewertung von Sprachmodellen
Bereiten einfache Auswertungen Eine leichtgewichtige Bibliothek zur Bewertung von Sprachmodellen unter Verwendung der Zero-Shot-Bewertungsmethode mit Gedankenketten-Eingabeaufforderung. Diese Bibliothek umfasst beliebte Bewertungsbenchmarks wie MMLU, MATH, GPQA, MGSM und HumanEval und zielt darauf ab, reale Nutzungsszenarien zu simulieren, um die Leistung von KI-Modellen bei komplexen Inferenzaufgaben zu bewerten.
Einige von Ihnen kennen vielleicht die beliebteste und umfassendste Evaluierungsbibliothek von OpenAI namens Bewertungen, was sich von einfachen Auswertungen unterscheidet.
Tatsächlich zeigt die Seite README Die Simple-Evals-Spezifikation weist darauf hin, dass sie nicht als Ersatz für die Bibliothek gedacht ist. Bewertungen.
Warum also verwenden wir einfache Evaluierungen?
Die einfache Antwort ist, dass einfache Auswertungen Es verfügt über integrierte Bewertungstexte für die von uns angestrebten Inferenzstandards (wie etwa GPQA), die in der Bibliothek fehlen. Bewertungen.
Darüber hinaus habe ich außer simple-evals keine anderen Tools oder Plattformen gefunden, die eine direkte und native Möglichkeit in der Sprache bieten. Python Zur Ausführung vieler wichtiger Standards, wie z. B. GPQA, insbesondere bei der Arbeit mit Ollama.
(7) Bewertungsergebnisse
Im Rahmen der Bewertung habe ich ausgewählt: 20 zufällige Fragen Aus dem GPQA-Diamond-Fragensatz mit 198 Fragen zum Bearbeiten Destilliergerät Form 14B. Insgesamt dauerte es 216 Minuten, also ungefähr 11 Minuten pro Frage.
Das Ergebnis war etwas enttäuschend, da es 10% Nur, was deutlich niedriger ist als das gemeldete Ergebnis von 73.3 % für das Modell 1B DeepSeek-R671.
Das Hauptproblem, das mir aufgefallen ist, ist, dass während intensiver innerer Überlegungen, Das Modell konnte häufig entweder keine Antwort erzeugen (z. B. wurden als letzte Ausgabezeilen Inferenzcodes zurückgegeben) oder lieferte eine Antwort, die nicht dem erwarteten Multiple-Choice-Format entsprach (z. B. Antwort: A).
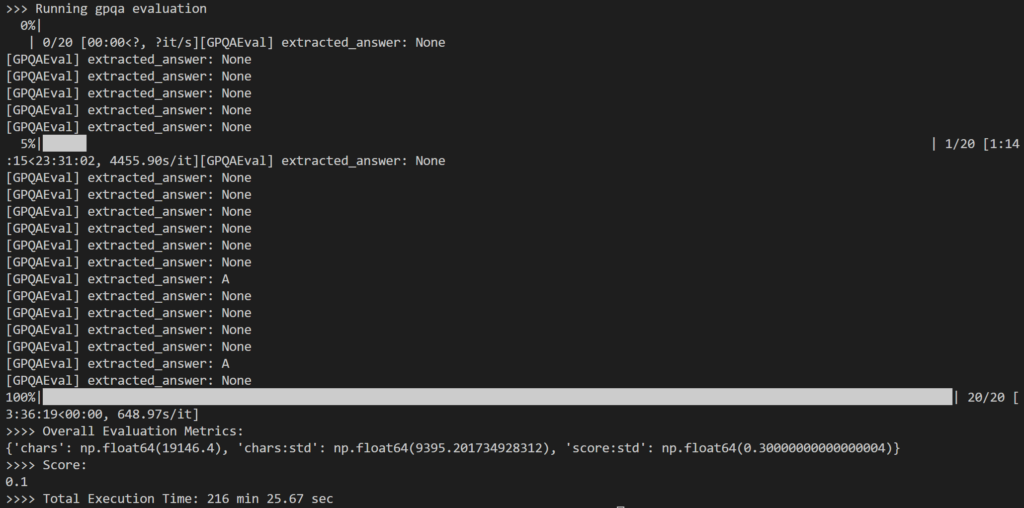
Wie oben gezeigt, lauteten viele der Ausgaben wie folgt: None Weil die Regex-Logik in Simple-Evals das erwartete Antwortmuster in der LLM-Antwort nicht erkennen konnte.
während die menschenähnliches Denken Es war interessant zu beobachten, da ich hinsichtlich der Genauigkeit bei der Beantwortung der Fragen eine bessere Leistung erwartet hatte.
Ich habe auch online Benutzer gesehen, die erwähnen, dass selbst das größere 32B-Modell nicht so gut funktioniert wie das o1. Dies hat Zweifel an der Nützlichkeit destillierter Inferenzmodelle aufkommen lassen, insbesondere wenn diese trotz der Generierung langer Schlussfolgerungen Schwierigkeiten haben, korrekte Antworten zu liefern.
GPQA-Diamond ist jedoch ein sehr anspruchsvoller Benchmark, sodass diese Modelle für einfachere Inferenzaufgaben dennoch nützlich sein können. Auch der geringere Rechenleistungsbedarf macht es einfacher.
Darüber hinaus empfahl das DeepSeek-Team, im Rahmen des Benchmarking-Prozesses mehrere Tests durchzuführen und die Ergebnisse zu mitteln – etwas, das ich aus Zeitgründen übersehen habe.
(8) Detaillierte Schritt-für-Schritt-Anleitung
Bis zu diesem Punkt haben wir die grundlegenden Konzepte und wichtigsten Schlussfolgerungen behandelt.
Wenn Sie bereit sind für eine praktische, technische Erfahrung, bietet dieser Abschnitt einen detaillierten Einblick in die internen Mechanismen und die schrittweise Implementierung. Dieser praktische technische Leitfaden vermittelt Ihnen ein umfassendes Verständnis der Funktionsweise des Systems.
Zum Anzeigen (oder Kopieren) Begleitendes GitHub-Repository Folgen. Die Anforderungen für die Einrichtung einer virtuellen Umgebung finden Sie hier. hier.
(i) Ersteinrichtung – Ollama
Wir beginnen mit dem Herunterladen von Ollama. Besuchen
Ollama-Downloadseite, wählen Sie Ihr Betriebssystem und folgen Sie den entsprechenden Installationsanweisungen.
Sobald die Installation abgeschlossen ist, starten Sie Ollama, indem Sie auf die Ollama-Anwendung (für Windows und macOS) doppelklicken oder den Befehl ausführen ollama serve Im Terminal.
(ii) Ersteinrichtung – OpenAI simple-evals
Das Simple-Evals-Setup ist relativ einzigartig.
Während simple-evals sich als Bibliothek präsentiert, Das Fehlen von Dateien __init__.py Im Repository bedeutet, dass es nicht als richtiges Python-Paket strukturiert ist., was zu Importfehlern nach dem lokalen Klonen des Repositorys führt. Dies bedeutet, dass es sich nicht um ein Standard-Python-Paket im Sinne der üblicherweise in der Softwareentwicklung verwendeten Sprache handelt.
Da es auch nicht auf PyPI veröffentlicht ist und Standard-Verpackungsdateien wie setup.py Oder pyproject.tomlEs kann nicht installiert werden über pip. Dies stellt für neue Entwickler eine gewisse Herausforderung dar.
Glücklicherweise können wir Git-Untermodule Als direkte Alternativlösung. Mit diesen Modulen können Sie ein Git-Repository in ein anderes integrieren, wodurch die Verwaltung von Abhängigkeiten vereinfacht wird.
„`html
Ein Git-Submodul ermöglicht es uns, den Inhalt eines anderen Git-Repositorys in unser Projekt einzubinden. Es zieht Dateien aus einem externen Repository (z. B. Simple-Evals), behält ihren Verlauf jedoch getrennt bei.
Sie können eine von zwei Methoden (A oder B) wählen, um den Inhalt einfacher Auswertungen zu extrahieren:
(a) Wenn Sie mein Projekt-Repository klonen
Mein Projekt-Repository enthält bereits simple-evals Als Untermodul können Sie einfach Folgendes ausführen:
git submodule update --init --recursive(b) Wenn Sie es einem neu erstellten Projekt hinzufügen.
Um simple-evals manuell als Untermodul hinzuzufügen, führen Sie Folgendes aus:
git submodule add https://github.com/openai/simple-evals.git simple_evalsملاحظة: Das simple_evals Am Ende (mit unterstreichen) ist sehr wichtig. Es gibt den Ordnernamen an, wobei stattdessen ein Bindestrich verwendet wird (d. h. einfache-evals) können später zu Importproblemen führen.
Letzter Schritt (für beide Methoden)
Nachdem Sie den Inhalt des Repository abgerufen haben, müssen Sie eine Datei erstellen. __init__.py Im Ordner leeren simple_evals Das neu erstellte kann als Einheit importiert werden. Sie können es manuell erstellen oder den folgenden Befehl verwenden:
touch simple_evals/__init__.py(iii) Abrufen des DeepSeek-R1-Modells über Ollama
Der nächste Schritt besteht darin, das lokal destillierte Modell Ihrer Wahl (z. B. 14B) mit diesem Befehl herunterzuladen:
Eine Liste der verfügbaren DeepSeek-R1-Modelle finden Sie auf Ollama. hier. Für eine optimale Leistung wird empfohlen, die neueste Version der Vorlage zu verwenden.
ollama pull deepseek-r1:14b(Viertens) Geben Sie die Einstellungen an
Wir definieren die Parameter in der YAML-Einstellungsdatei, wie unten gezeigt:
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # Modellname (übereinstimmung mit der Ollama-Modellliste) MODEL_TEMPERATURE: 0.6 # Zwischen 0.5 und 0.7 für DeepSeek-R1 einstellen EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
Die Modelltemperatur ist eingestellt auf 0.6 (Im Vergleich zum typischen Standardwert von 0). Dies entspricht den Nutzungsempfehlungen von DeepSeek, die einen Temperaturbereich von 0.5 bis 0.7 vorschlagen (0.6 wird empfohlen). Um unendliche Wiederholungen oder inkohärente Ausgaben zu vermeiden. Diese Einstellung ist erforderlich, um die Qualität der Ausgabe zu verbessern und ihre Konsistenz sicherzustellen.
Verpassen Sie nicht die Chance, sich umzusehen Die einzigartigen und interessanten Nutzungsempfehlungen von DeepSeek-R1 – insbesondere für Benchmarks – um eine optimale Leistung bei der Verwendung von DeepSeek-R1-Modellen sicherzustellen.
EVAL_N_EXAMPLES Mit diesem Parameter wird die Anzahl der Fragen aus dem vollständigen Satz von 198 Fragen festgelegt, die bei der Bewertung verwendet werden. Dieser Parameter ist notwendig, um den Evaluierungsprozess an die verfügbaren Ressourcen und die spezifischen Testziele anzupassen.
(v) Einrichten des Sampler-Codes
Um Ollama-basierte Sprachmodelle innerhalb des Simple-Evals-Frameworks zu unterstützen, erstellen wir eine benutzerdefinierte Wrapper-Klasse namens OllamaSampler Und behalte es in dir utils/samplers/ollama_sampler.py. Sampler ist eine wesentliche Komponente beim Testen und Bewerten der Leistung von Sprachmodellen.
# utils/samplers/ollama_sampler.py importiere ollama-Klasse OllamaSampler: def __init__(selbst, Modellname=None, Temperatur=0): selbst.Modellname = Modellname selbst.Temperatur = Temperatur def __call__(selbst, Eingabeaufforderungsnachrichten): Eingabeaufforderungstext = Eingabeaufforderungsnachrichten[-1]["Inhalt"] Antwort = ollama.chat(Modell=selbst.Modellname, Nachrichten=[{"Rolle": "Benutzer", "Inhalt": Eingabeaufforderungstext}], Optionen={"Temperatur": selbst.Temperatur} ) Antwortinhalt = Antwort["Nachricht"]["Inhalt"] returniere Antwortinhalt def _pack_message(selbst, Inhalt, Rolle): returniere {"Rolle": Rolle, "Inhalt": Inhalt}
In diesem Zusammenhang bedeutet es Sampler (Samplifier) Eine Python-Klasse, die basierend auf einer gegebenen Eingabeaufforderung eine Ausgabe aus einem Sprachmodell generiert. Dieses Tool ist von entscheidender Bedeutung, um sicherzustellen, dass das Modell vielfältige und repräsentative Antworten generiert.
Da die Sampler in Simple-Evals nur Anbieter wie OpenAI und Claude abdecken, benötigen wir eine Sampler-Klasse, die eine mit Ollama kompatible Schnittstelle bereitstellt. Dadurch wird eine nahtlose Integration in das Bewertungsframework gewährleistet.
aufstehen OllamaSampler Extrahiert eine GPQA-Frageaufforderung, sendet sie bei einer angegebenen Temperatur an das Formular und gibt eine Antwort im Klartext zurück. Die Temperatur ist ein wichtiger Parameter, der die Zufälligkeit der Ausgabe steuert.
Methode enthalten _pack_message Um sicherzustellen, dass das Ausgabeformat den Erwartungen der Auswertungsskripte in Simple-Evals entspricht. Dies gewährleistet Konsistenz und einfache Analyse.
6. Erstellen Sie ein Evaluierungsskript
Der folgende Code zeigt, wie die Auswertungsimplementierung in einer Datei eingerichtet wird. main.py, einschließlich der Verwendung der Kategorie GPQAEval Aus der Simple-Evals-Bibliothek zum Ausführen von GPQA-Benchmarktests.
Funktion run_eval() Es handelt sich um ein konfigurierbares Laufzeittool zur Evaluierung, das große Sprachmodelle (LLMs) über Ollama anhand von Standards wie GPQA testet. Diese Funktion ist erforderlich, um die Leistung von Modellen genau zu bewerten.
# main.py def run_eval(): start_time = time.time() # Konfigurationsdatei laden config = load_config("config/config.yaml") # Ollama-Sampler initialisieren (Wrapper um Ollama-Chat) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # Zu verwendende Auswertungsklasse basierend auf EVAL_BENCHMARK auswählen eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> {eval_benchmark}-Auswertung ausführen") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # Standard 1 "num_examples": config["EVAL_N_EXAMPLES"], # Festlegen bis 20 "Variante": config["GPQA_VARIANT"], # GPQA-Diamond-Teilmenge } sonst: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # Instanziieren und führen Sie die entsprechende Auswertung aus evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # Auswertung mit Sampler ausführen end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # Gesamtzeit berechnen # Das zurückgegebene Ergebnis ist ein EvalResult, das eine Liste mit SingleEvalResults und aggregierten Metriken enthält print(">>>> Gesamtbewertungsmetriken:", results.metrics) print(">>>> Score:", results.score) print(f">>>> Gesamtausführungszeit: {int(Minuten)} min {Sekunden:.2f} Sek.") if __name__ == "__main__": # GPQA-Auswertungsausführung ausführen run_eval()
Die Funktion lädt die Einstellungen aus der Konfigurationsdatei, richtet die entsprechende Auswertungsklasse aus simple-evals ein und führt das Modell durch einen einheitlichen Auswertungsprozess. Es wird in einer Datei gespeichert. main.py, die mit dem Befehl ausgeführt werden kann python main.py. Dadurch wird ein konsistenter und wiederholbarer Bewertungsprozess gewährleistet.
Indem wir die oben genannten Schritte befolgten, haben wir den GPQA-Diamond-Benchmark erfolgreich auf dem destillierten Modell DeepSeek-R1 eingerichtet und ausgeführt. Dieser Prozess liefert wertvolle Erkenntnisse über die Fähigkeiten des Modells.
Das Endergebnis
In diesem Artikel untersuchen wir, wie wir Tools wie Ollama und OpenAIs simple-evals kombinieren können, um aus DeepSeek-R1 destillierte Modelle zu untersuchen und zu bewerten, mit einem Schwerpunkt auf Leistungsbewertung großer Sprachmodelle.
Die destillierten Modelle erreichen bei anspruchsvollen Inferenz-Benchmarks wie GPQA-Diamond möglicherweise noch nicht das Niveau des ursprünglichen Modells mit 671 Milliarden Parametern. Es veranschaulicht jedoch, wie durch Destillation der Zugriff auf die Inferenzfunktionen großer Sprachmodelle (LLMs) erweitert werden kann. Verbesserter Zugriff auf große Sprachmodelle Dies ist ein wichtiges Ziel in diesem Bereich.
Trotz geringerer Leistung bei komplexen Aufgaben auf PhD-Niveau können diese kleineren Varianten dennoch in weniger anspruchsvollen Szenarien anwendbar sein und ebnen den Weg für eine effiziente lokale Bereitstellung auf einer größeren Bandbreite von Geräten. Dies trägt dazu bei Lokales Bereitstellen großer Sprachmodelle Effizient.
Kommentarfunktion ist geschlossen.