

Erreichen von Sicherheit in großen Sprachmodellen (LLMs) durch intelligente Entscheidungsschaltungen
Unsicherheit ist in der Technologie nichts Neues – alle modernen Systeme überwinden unsichere Ein- und Ausgaben mithilfe mathematisch erprobter Kontrollstrukturen.
Das Versprechen von KI-Agenten hat die Welt im Sturm erobert. Agenten können mit der Welt um sie herum interagieren, Artikel schreiben (aber nicht diesen), in Ihrem Namen Maßnahmen ergreifen und im Allgemeinen den schwierigen Teil der Automatisierung jeder Aufgabe einfach und zugänglich machen.
Die Agenten konzentrieren sich auf die schwierigsten Teile des Betriebs und lösen Probleme schnell. Manchmal zu schnell – Wenn Ihr agentenbasierter Prozess einen Menschen erfordert, der über das Ergebnis entscheidet, kann die menschliche Überprüfungsphase zu einem Engpass im Prozess werden.
Ein Beispiel für einen agentenbasierten Prozess ist die Verarbeitung und Klassifizierung von Kundentelefonanrufen. Sogar einem Agenten mit einer Genauigkeit von 99.95 % unterlaufen beim Abhören von 5 Anrufen fünf Fehler. Obwohl der Agent dies weiß, kann er es Ihnen nicht sagen. Welche 5 von 10,000 Anrufen wurden falsch klassifiziert.

Bei der „LLM-als-Richter“-Technik handelt es sich um eine Technik, bei der Sie jeden Input in einen anderen LLM-Prozess einspeisen, um zu beurteilen, ob die aus dem Input resultierende Ausgabe richtig ist. Da es sich hierbei jedoch um einen weiteren LLM-Prozess handelt, kann es auch hier zu Ungenauigkeiten kommen. Diese beiden Wahrscheinlichkeitsoperationen erstellen eine Konfusionsmatrix mit echten Positiven, falschen Negativen, echten Negativen und falschen Positiven.
Mit anderen Worten: Ein Eintrag, der durch einen LLM-Prozess richtig klassifiziert wird, kann von seinem LLM-Bewerter als falsch beurteilt werden und umgekehrt.
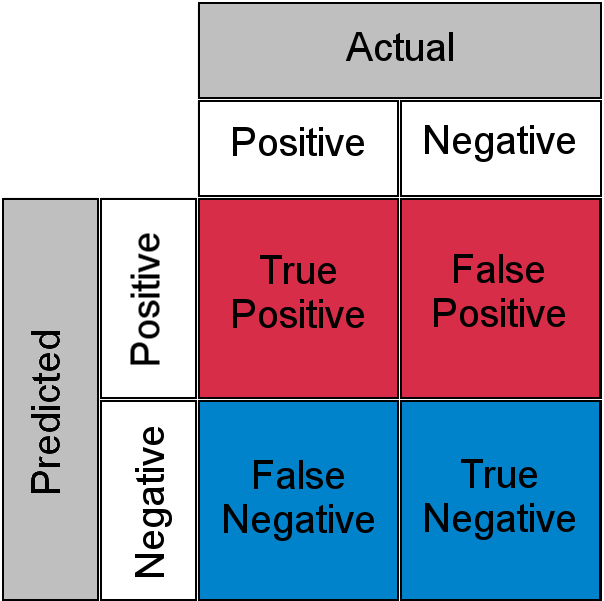
deswegen " Das Unbekannte bekannt „Bei einem sensiblen Arbeitspensum muss ein Mensch alle 10,000 Anrufe prüfen und verstehen. Wir haben wieder das gleiche Engpassproblem.“
Wie können wir mehr statistische Sicherheit in unsere agentengesteuerten Prozesse integrieren? In diesem Beitrag baue ich ein System auf, das uns mehr Sicherheit in unseren agentengesteuerten Prozessen ermöglicht, es auf eine beliebige Anzahl von Agenten verallgemeinert und eine Kostenfunktion entwickelt, die zukünftige Investitionen in das System steuert. Der Code, den ich in diesem Beitrag verwende, ist in meinem Repository verfügbar. KI-Entscheidungsschaltungen.
KI-Entscheidungsschaltkreise
Das Erkennen und Korrigieren von Fehlern ist kein neues Konzept. Die Fehlerkorrektur ist in Bereichen wie der digitalen und analogen Elektronik von entscheidender Bedeutung. Sogar Fortschritte im Quantencomputing hängen von der Erweiterung der Fähigkeiten zur Fehlerkorrektur und -erkennung ab. Wir können uns von diesen Systemen inspirieren lassen und etwas Ähnliches mit KI-Agenten implementieren. Sie können beispielsweise Algorithmen der künstlichen Intelligenz Erweiterte Nutzung von Fehlerkorrekturtechniken in Kommunikationssystemen.
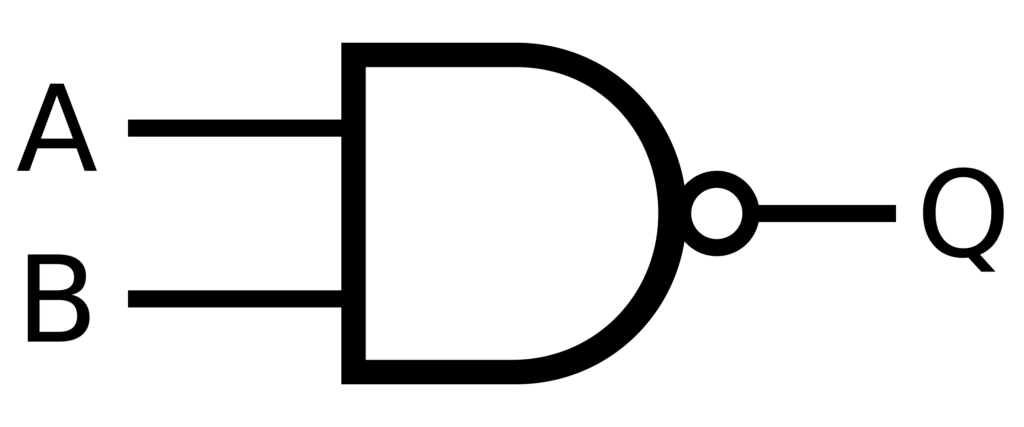
In der Booleschen Logik sind NAND-Gatter der heilige Gral der Berechnung, da sie jede beliebige Operation ausführen können. Es ist funktional vollständig, was bedeutet, dass jede logische Operation nur mit NAND-Gattern erstellt werden kann. Dieses Prinzip kann auf KI-Systeme angewendet werden, um robuste Entscheidungsstrukturen mit integrierter Fehlerkorrektur zu erstellen. Dies ermöglicht die Erstellung von neuronale Netze Zuverlässiger und in der Lage, unvollständige oder verrauschte Daten zu verarbeiten.
Von elektronischen Schaltkreisen zu intelligenten Entscheidungsfindungsschaltkreisen (KI)
So wie elektronische Schaltkreise Wiederholung und Überprüfung verwenden, um zuverlässige Berechnungen sicherzustellen, können Schaltkreise für intelligente Entscheidungsfindung (KI) mehrere Agenten mit unterschiedlichen Perspektiven verwenden, um zu genaueren Ergebnissen zu gelangen. Diese Schaltkreise können unter Verwendung von Prinzipien der Informationstheorie und der Booleschen Logik aufgebaut werden:
- Redundante Verarbeitung: Mehrere KI-Agenten verarbeiten dieselben Eingaben unabhängig voneinander, ähnlich wie moderne CPUs redundante Schaltkreise verwenden, um Hardwarefehler zu erkennen. Dieser Vorgang erhöht die Zuverlässigkeit des KI-Systems.
- Konsensmechanismen: Entscheidungsergebnisse werden mithilfe von Abstimmungssystemen oder gewichteten Durchschnittswerten kombiniert, ähnlich wie Mehrheitslogikgatter in der fehlertoleranten Elektronik. Diese Mechanismen stellen sicher, dass die endgültige Entscheidung den Konsens unter den Agenten widerspiegelt.
- Validierungsagenten: Spezialisierte KI-Auditoren prüfen die Plausibilität der Ausgabe und arbeiten dabei ähnlich wie Fehlererkennungscodes wie Paritätsbits Oder zyklische Redundanzprüfungen (CRC-Prüfungen). Diese Agenten verringern die Wahrscheinlichkeit, falsche Entscheidungen zu treffen.
- Human-in-the-Loop-Integration: Strategische menschliche Überprüfung an wichtigen Punkten im Entscheidungsprozess, ähnlich wie biometrische Systeme die menschliche Aufsicht als letzte Überprüfungsebene nutzen. Dadurch wird sichergestellt, dass wichtige Entscheidungen einer menschlichen Bewertung unterliegen.
Mathematische Grundlagen von Entscheidungsschaltkreisen in der Künstlichen Intelligenz
Die Zuverlässigkeit dieser Systeme kann mithilfe der Wahrscheinlichkeitstheorie quantitativ bestimmt werden.
Ein Faktor, der die Wahrscheinlichkeit eines Fehlers bestimmt, ist die im Laufe der Zeit beobachtete Genauigkeit eines Testdatensatzes, der in einem System wie LangSmith.

Für einen 90%igen Genauigkeitsfaktor beträgt die Ausfallwahrscheinlichkeit p_1، 1–0.9 Es beträgt 0.1 oder 10 %.

Die Wahrscheinlichkeit, dass zwei unabhängige Faktoren bei derselben Eingabe versagen, ist die Wahrscheinlichkeit, dass beide Faktoren genau sind, multipliziert mit der Wahrscheinlichkeit:
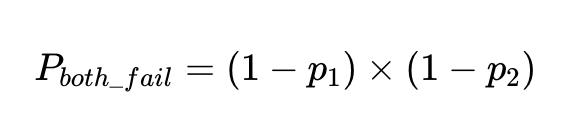
Wenn wir N Ausführungen mit diesen Clients haben, beträgt die Gesamtzahl der Fehler
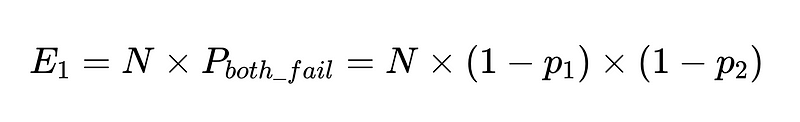
Bei 10,000 Ausführungen zwischen zwei unabhängigen Mitarbeitern mit einer Genauigkeit von 90 % beträgt die erwartete Anzahl von Fehlern also 100.
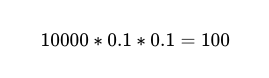
Wir wissen es jedoch immer noch nicht. Welche Von diesen 10,000 Telefonanrufen sind 100 tatsächliche Fehlschläge.
Wir können vier Erweiterungen dieser Idee kombinieren, um eine robustere Lösung bereitzustellen, die Vertrauen in jede gegebene Antwort schafft:
- Grundlegender Klassifikator (einfache Auflösung oben)
- Backup (einfache Lösung oben)
- Schema-Checker (z. B. 0.7-Auflösung)

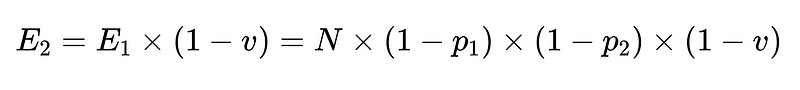
- Schließlich ein negativer Validator (n = Genauigkeit 0.6 zum Beispiel)
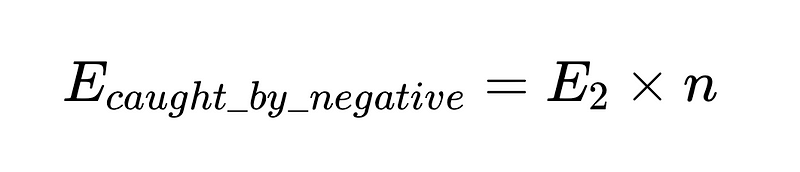
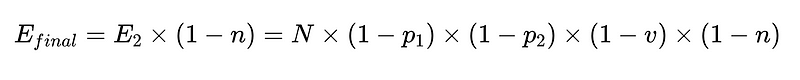
Um dies in Code umzusetzen (Das komplette Lager), können wir verwenden Python Basic:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESDurch die Kombination dieser Operationen mit Logik, Boolean Einfach ausgedrückt können wir eine ähnliche Genauigkeit und Vertrauen in jede Antwort erreichen:
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
Entscheidungslogik: Eine Schritt-für-Schritt-Erklärung
Schritt 1: Wenn das Qualitätskontrollsystem versagt
if not validation_result:Das bedeutet: „Wenn unser Qualitätskontrollexperte (Auditor) die Erstanalyse ablehnt, vertrauen Sie ihr nicht.“ Das System versucht dann, stattdessen die Backup-Meinung zu verwenden. Wenn auch diese Überprüfung fehlschlägt, wird der Fall zur Überprüfung durch einen menschlichen Spezialisten markiert. Dieses Verfahren stellt sicher, dass Sie sich nicht auf ungenaue Daten verlassen.
Einfach ausgedrückt: „Wenn mit unserer ersten Antwort etwas nicht stimmt, versuchen wir es mit unserer Ersatzmethode. Wenn auch diese fragwürdig ist, bitten wir einen menschlichen Experten um Hilfe.“ Dadurch wird sichergestellt, dass auch komplexe Fälle korrekt behandelt werden.
Schritt 2: Diskrepanzen beheben
if negative_check == 'no' and primary_result['call_type'] is not None:In diesem Schritt wird nach einer bestimmten Art von Diskrepanz gesucht: „Unser Negativprüfer zeigt an, dass es keinen Call-Typ geben sollte, aber unser Fundamentalanalyst hat trotzdem einen Put-Typ gefunden.“
In solchen Fällen verlässt sich das System auf den Fallback-Analysten, um die Gewinnschwelle zu erreichen:
- Wenn der Backup-Analyst zustimmt, dass kein Anruftyp vorliegt, wird dieser an das menschliche Element gesendet.
- Wenn der Backup-Analyst mit dem primären Analysten übereinstimmt, wird es akzeptiert, jedoch mit mittlerer Sicherheit.
- Wenn der Backup-Analyst einen anderen Anruftyp hat ← wird dieser an das menschliche Element gesendet
Das ist so, als würde man sagen: „Wenn ein Experte sagt, das ist nicht klassifizierbar, ein anderer aber, dann brauchen wir einen Tie-Breaker oder einen menschlichen Richter.“ Dieser Mechanismus ist notwendig, um eine genaue Anruftypklassifizierung sicherzustellen und potenzielle Fehler zu reduzieren.
Schritt 3: Wenn sich die Experten einig sind
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:Wenn sowohl der primäre Analyst als auch der Backup-Analyst unabhängig voneinander zum gleichen Schluss kommen, kennzeichnet das System diesen als „hohes Vertrauen“ – das ist das beste Szenario. Dieser Idealzustand tritt ein, wenn mehrere Analysen eindeutig übereinstimmen.
Einfach ausgedrückt: „Wenn zwei verschiedene Experten mit unterschiedlichen Methoden unabhängig voneinander zum gleichen Schluss kommen, können wir ziemlich sicher sein, dass ihre Schlussfolgerung richtig ist.“ Dies stellt den Konsens der Experten dar und ist ein starker Indikator für Genauigkeit und Zuverlässigkeit.
Schritt 4: Standardverarbeitung
Wenn keine der Sonderbedingungen zutrifft, verwendet das System standardmäßig das Ergebnis des primären Analysten mit „mittlerer“ Zuverlässigkeit. Wenn der Hauptanalyst die Art des Anrufs nicht identifizieren kann, markiert er den Fall zur Überprüfung durch einen spezialisierten menschlichen Analysten.
Die Bedeutung dieses Ansatzes zur Reduzierung von Fehlern
Diese Logik trägt zum Aufbau eines starken Systems bei, indem sie:
- Reduzierung falscher PositivmeldungenDas System bietet nur dann eine hohe Zuverlässigkeit, wenn mehrere Methoden übereinstimmen, wodurch Fehlalarme erheblich reduziert werden.
- Widersprüche entdeckenWenn sich verschiedene Teile des Systems unterscheiden, verringert dies entweder das Vertrauen oder eskaliert die Angelegenheit an menschliche Prüfer. Dadurch wird sichergestellt, dass kein potenzielles Problem übersehen wird.
- Intelligente EskalationMenschliche Prüfer sehen sich nur die Fälle an, die wirklich ihre Expertise erfordern. Dadurch wird die Effizienz des Prüfprozesses gesteigert und die Belastung der Personalressourcen verringert.
- VertrauensbezeichnungDie Ergebnisse beinhalten das Vertrauensniveau des Systems, sodass nachfolgende Prozesse Ergebnisse mit hohem und mittlerem Vertrauen unterschiedlich behandeln können, was für fundierte Entscheidungen von entscheidender Bedeutung ist.
Dieser Ansatz ähnelt der Art und Weise, wie in der Elektronik redundante Schaltkreise und Abstimmungsmechanismen verwendet werden, um zu verhindern, dass Fehler zu Systemausfällen führen. In KI-Systemen kann diese Art durchdachter Integrationslogik die Fehlerquote erheblich senken und gleichzeitig menschliche Prüfer nur dort effizient einsetzen, wo sie den größten Mehrwert bieten. Dadurch wird sichergestellt, dass die Ressourcen optimiert und gleichzeitig Fehler reduziert werden, was zu einem zuverlässigeren und genaueren System führt.
Beispiel
Im Jahr 2015 veröffentlichte das Wasserwerk der Stadt Philadelphia Kundenanrufstatistik nach Kategorie. Das Verstehen von Kundenanrufen ist für Agenten ein sehr alltäglicher Prozess. Anstatt jeden Kundenanruf von einem Menschen abhören zu lassen, kann ein Agent den Anruf viel schneller abhören, Informationen extrahieren und den Anruf für die weitere Datenanalyse kategorisieren. Für die Wasserwirtschaft ist dies wichtig, denn je früher kritische Probleme erkannt werden, desto schneller können diese gelöst werden.
Wir können ein Erlebnis aufbauen. Ich habe ein großes Sprachmodell (LLM) verwendet, um gefälschte Transkripte der betreffenden Telefongespräche zu generieren, indem ich gefragt habe: „Generieren Sie anhand der folgenden Klasse eine Kurzversion dieses Telefongesprächs: Hier sind einige dieser Beispiele mit der vollständigen verfügbaren Datei. hier:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}Jetzt können wir das Experiment mit einer traditionelleren Bewertung unter Verwendung eines großen Sprachmodells als Richter einrichten (Vollständige Implementierung hier):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeIndem wir nur den Text an ein großes Sprachmodell (LLM) übergeben, können wir das wahre Klassenwissen aus der zurückgegebenen extrahierten Klasse isolieren und vergleichen.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultDie Ausführung auf dem gesamten synthetischen Datensatz mit Claude 3.7 Sonnet (dem neuesten Modell zum Zeitpunkt der Erstellung dieses Artikels) ist sehr leistungsstark, da 91 % der Anrufe korrekt klassifiziert werden:
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}Wenn es sich um echte Anrufe handeln würde und wir keine Vorkenntnisse über die Kategorie hätten, müssten wir trotzdem alle 100 Telefonanrufe überprüfen, um die 9 falsch klassifizierten Anrufe zu finden.
Durch die Anwendung unserer leistungsstarken Entscheidungsschaltung oben erhalten wir ähnliche Genauigkeitsergebnisse zusammen mit Vertrauen In diesen Antworten. In diesem Fall beträgt die Gesamtgenauigkeit 87 %, bei unseren Antworten mit hoher Zuverlässigkeit jedoch 92.5 %.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}Wir benötigen eine 100-prozentige Genauigkeit unserer Antworten mit hoher Zuverlässigkeit, es bleibt also noch einiges zu tun. Dieser Ansatz ermöglicht es uns, tiefer einzudringen in Grund Ungenauigkeit von Antworten mit hoher Zuverlässigkeit. In diesem Fall erfassen schwache Behauptungen und einfache Überprüfungsmöglichkeiten nicht alle Probleme, was zu Klassifizierungsfehlern führt. Diese Fähigkeiten können iterativ verbessert werden, um bei Antworten mit hoher Zuverlässigkeit eine Genauigkeit von 100 % zu erreichen.
Verbesserungen am Filtersystem, um das Vertrauen in die Ergebnisse zu erhöhen.
Das aktuelle System stuft Antworten als „hohes Vertrauen“ ein, wenn die primären und Backup-Analysten übereinstimmen. Um eine höhere Genauigkeit zu erreichen, müssen wir selektiver vorgehen, was als „hohes Vertrauen“ gilt.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}Durch das Hinzufügen zusätzlicher Qualifizierungskriterien erhalten wir zwar weniger Ergebnisse mit hoher Zuverlässigkeit, diese sind jedoch genauer. Ziel dieser Verbesserung des Filtersystems ist es, Fehler zu reduzieren und die Zuverlässigkeit der als qualitativ hochwertig eingestuften Daten zu erhöhen.
Zusätzliche Verifizierungstechniken: Verbesserung der Analysegenauigkeit
Hier sind einige weitere Ideen zur Verbesserung Ihres Datenvalidierungs- und Analyseprozesses:
TertiäranalysatorFügen Sie eine dritte unabhängige Analysemethode hinzu. Diese Methode dient als zusätzliche Überprüfungsebene, indem sie die Ergebnisse zweier unterschiedlicher Analysemethoden mit dem Ergebnis einer dritten Methode vergleicht, um eine höhere Genauigkeit sicherzustellen und die Möglichkeit von Fehlern zu verringern.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:Historischer Musterabgleich:Vergleichen Sie die Ergebnisse mit historisch korrekten Ergebnissen (denken Sie an die Vektorsuche). Bei dieser Technik werden zuverlässige historische Daten als Referenz verwendet und aktuelle Ergebnisse damit verglichen, um etwaige Abweichungen oder Inkonsistenzen zu erkennen. Es kann als eine Art „Gedächtnis“ für Analysen betrachtet werden, das dabei hilft, Anomalien oder unerwartete Situationen zu erkennen.
if similarity_to_known_correct_cases(primary_result) > 0.95:Adversarial TestingWenden Sie kleine Variationen auf die Eingaben an und prüfen Sie, ob die Klassifizierung stabil bleibt. Ziel dieser Methode ist es, die Robustheit und Robustheit eines Klassifizierungssystems zu testen, indem es geringfügigen Änderungen in den Daten ausgesetzt wird. Wenn das System sehr empfindlich auf diese Änderungen reagiert, kann dies auf potenzielle Schwächen oder Verzerrungen hinweisen.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
Allgemeine Formel für menschliche Eingriffe in ein LLM-Extraktionssystem
Die vollständige Herleitung ist hier verfügbar..
- N = Gesamtzahl der Ausführungen (10,000 in unserem Beispiel)
- p_1 = Genauigkeit des Basisparsers (0.8 in unserem Beispiel)
- p_2 = Genauigkeit des Fallback-Parsers (0.8 in unserem Beispiel)
- v = Effektivität des Schema-Validators (0.7 in unserem Beispiel)
- n = Wirksamkeit des Negativprüfers (0.6 in unserem Beispiel)
- H = Anzahl der erforderlichen menschlichen Eingriffe
- E_final = letzte nicht erkannte Fehler
- m = Anzahl der unabhängigen Wirtschaftsprüfer
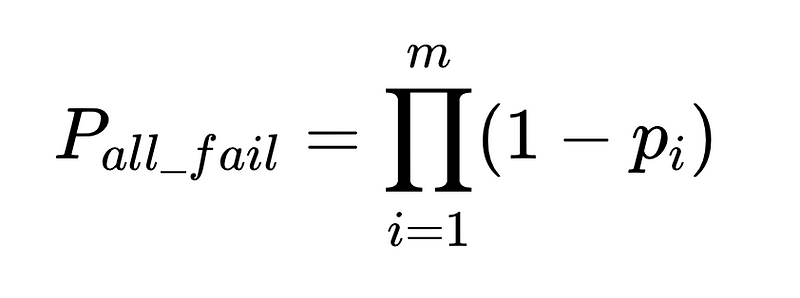
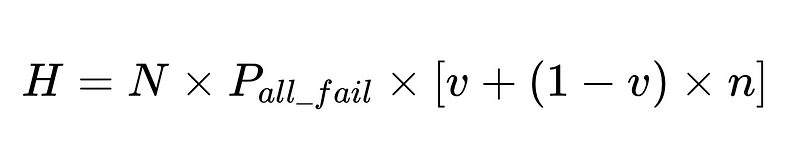
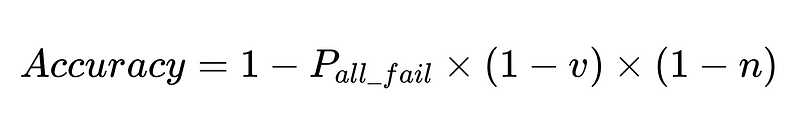
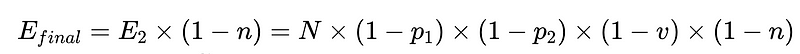
Optimales Systemdesign
Die Gleichung liefert wichtige Erkenntnisse zur Genauigkeit eines Systems zur Verarbeitung natürlicher Sprache (NLP):
- Durch das Hinzufügen von Parsern wird der Overhead reduziert, aber die Gesamtgenauigkeit verbessert.
- Die Systemgenauigkeit wird begrenzt durch:
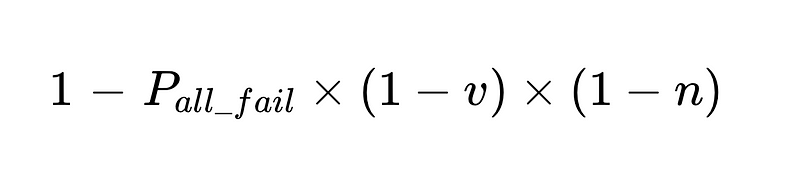
- Menschliche Eingriffe sind verhältnismäßig Direkt Mit insgesamt N Hinrichtungen.
Beispielsweise:
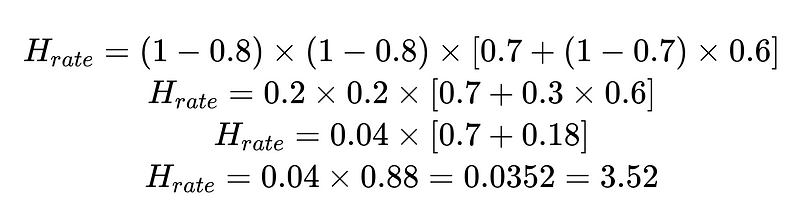
Mithilfe der berechneten menschlichen Interventionsrate (H_rate) können wir die Wirksamkeit unserer Lösung in Echtzeit verfolgen. Wenn die menschliche Eingriffsrate über 3.5 % steigt, wissen wir, dass das System versagt. Wenn die menschliche Eingriffsrate konstant auf weniger als 3.5 % sinkt, wissen wir, dass unsere Optimierungen wie erwartet funktionieren.
Kostenfunktion
Wir können auch eine Kostenfunktion erstellen, die uns hilft, unser System zu verbessern. Die Kostenfunktion ist ein leistungsfähiges Analysetool zur Bewertung der finanziellen Leistung eines Systems und zur Identifizierung potenzieller Verbesserungsbereiche.
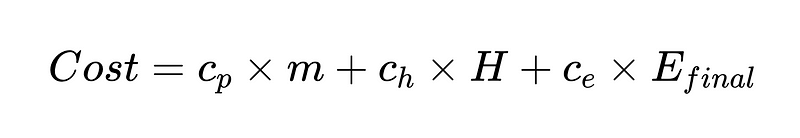
Wo:
- c_p = laufende Kosten pro Parser (0.10 $ in unserem Beispiel)
- m = Anzahl der Ausführungen des Parsers (in unserem Beispiel 2 * N)
- H = Anzahl der Fälle, die menschliches Eingreifen erfordern (352 in unserem Beispiel)
- c_h = Kosten eines menschlichen Eingriffs (z. B. 200 $: 4 Stunden à 50 $/Stunde)
- c_e = Kosten eines unentdeckten Fehlers (z. B. 1000 $)
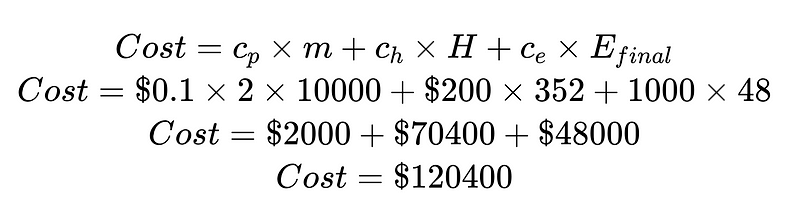
Indem wir die Kosten durch die Kosten menschlichen Eingreifens und die Kosten unentdeckter Fehler teilen, können wir das Gesamtsystem verbessern. In diesem Beispiel können wir uns auf die Verbesserung zuverlässiger Ergebnisse konzentrieren, wenn die Kosten menschlichen Eingreifens (70,400 $) unerwünscht und teuer sind. Wenn die Kosten unentdeckter Fehler (48,000 $) unerwünscht und teuer sind, können wir Plus-Syntaxanalysatoren einführen, um die Rate unentdeckter Fehler zu reduzieren.
Natürlich sind Kostenfunktionen am nützlichsten, um herauszufinden, wie sich die von ihnen beschriebenen Situationen verbessern lassen.
Um im obigen Szenario die Anzahl der nicht erkannten Fehler, E_final, um 50 % zu reduzieren, wobei
- p1 und p2 = 0.8,
- v = 0.7 und
- n = 0.6
Wir haben drei Möglichkeiten:
- Hinzufügen eines neuen Grammatikparsers mit 50 % Genauigkeit und dessen Einbindung als sekundärer Parser. Beachten Sie, dass dies mit einem Kompromiss verbunden ist: Die Kosten für den Betrieb der Plus-Grammatikparser steigen zusammen mit den Kosten für menschliches Eingreifen.
- Verbessern Sie vorhandene Grammatikparser jeweils um 10 %. Dies kann aufgrund der Schwierigkeit der von diesen Syntaxanalysatoren ausgeführten Aufgabe möglich sein oder auch nicht.
- Verbessern Sie den Auditprozess um 15 %. Auch hier erhöhen sich die Kosten durch menschliches Eingreifen.
Die Zukunft des KI-Vertrauens: Vertrauensbildung durch extreme Präzision
Da KI-Systeme zunehmend in wichtige Aspekte von Wirtschaft und Gesellschaft integriert werden, wird das Streben nach optimaler Genauigkeit immer wichtiger, insbesondere bei kritischen Anwendungen. Durch die Übernahme dieser schaltungsinspirierten Ansätze zur KI-Entscheidungsfindung können wir Systeme erstellen, die nicht nur effizient skalieren, sondern auch das tiefe Vertrauen gewinnen, das nur durch konsistente, zuverlässige Leistung entsteht. Die Zukunft liegt nicht in leistungsfähigeren Einzelmodellen, sondern in sorgfältig konzipierten Systemen, die mehrere Perspektiven mit strategischer menschlicher Aufsicht kombinieren.
So wie sich die digitale Elektronik aus unzuverlässigen Komponenten zu Computern entwickelt hat, denen wir unsere wichtigsten Daten anvertrauen, befinden sich KI-Systeme derzeit auf einem ähnlichen Weg. Die in diesem Artikel beschriebenen Frameworks stellen die Blaupausen für das dar, was letztendlich zur Standardarchitektur für unternehmenskritische KI werden wird – Systeme, die Zuverlässigkeit nicht nur versprechen, sondern auch mathematisch garantieren. Die Frage ist nicht mehr, ob wir KI-Systeme mit nahezu perfekter Genauigkeit bauen können, sondern wie schnell wir diese Prinzipien in unseren wichtigsten Anwendungen implementieren können.
Kommentarfunktion ist geschlossen.