

Meta bringt KI-Modellen die Kunst bei, zwischen wichtigen und anderen Befehlen zu unterscheiden.
Denkmodelle wie OpenAI o1 und DeepSeek-R1 haben das Problem, dass sie zu viel nachdenken. Wenn Sie ihr eine einfache Frage stellen, wie etwa „Was ist 1+1?“, wird sie einige Sekunden nachdenken, bevor sie antwortet.

Im Idealfall sollten KI-Modelle wie Menschen in der Lage sein, zu entscheiden, wann eine direkte Antwort gegeben werden muss und wann zusätzliche Zeit und Ressourcen zum Nachdenken vor einer Antwort eingeplant werden müssen. Und das tut es neue Technologie Präsentiert von Forschern in Meta-KI وUniversität von Illinois in Chicago Durch das Trainieren von Modellen zur Zuweisung von Inferenzbudgets basierend auf der Abfrageschwierigkeit. Dies führt zu schnelleren Reaktionen, geringeren Kosten und einer besseren Zuweisung der Rechenressourcen.
kostspielige Argumentation
Große Sprachmodelle (LLMs) können ihre Leistung bei Denkaufgaben verbessern, wenn sie längere Gedankenketten produzieren, die oft als „Gedankenketten“ (CoT) bezeichnet werden. Der Erfolg der Ideenkettentechnik hat zu einer ganzen Reihe von Techniken zur Skalierung der Inferenzzeit geführt, die das Modell zwingen, tiefer über das Problem nachzudenken, mehrere Antworten zu generieren und zu überprüfen und die beste auszuwählen.
Die Mehrheitswahl (MV) ist eine der wichtigsten Methoden in Schlussfolgerungsmodellen, bei der mehrere Antworten generiert werden und die am häufigsten gestellte Antwort ausgewählt wird. Das Problem bei diesem Ansatz besteht darin, dass das Modell ein einheitliches Verhalten annimmt, jede Eingabe als schwieriges Denkproblem behandelt und unnötige Ressourcen verbraucht, um mehrere Antworten zu generieren.
Intelligentes Denken
Das neue Forschungspapier schlägt eine Reihe von Trainingstechniken vor, die die Reaktionseffizienz von Argumentationsmodellen steigern. Der erste Schritt ist das „Sequentielle Abstimmen“ (SV), bei dem das Modell den Denkprozess abbricht, sobald eine bestimmte Antwort eine bestimmte Anzahl von Malen vorgekommen ist. Beispielsweise wird im Formular verlangt, maximal acht Antworten zu generieren und die Antwort auszuwählen, die mindestens dreimal vorkommt. Wenn dem Modell die oben genannte einfache Abfrage gegeben wird, sind die ersten drei Antworten wahrscheinlich ähnlich, was zu einem frühzeitigen Abbruch führt und Zeit und Rechenressourcen spart.
Ihre Experimente zeigen, dass SV bei mathematischen Wettbewerbsproblemen klassischem MV überlegen ist, wenn es die gleiche Anzahl von Antworten generiert. Allerdings erfordert SV zusätzliche Anweisungen und Codegenerierung, sodass es hinsichtlich des Code-zu-Präzision-Verhältnisses mit MV gleichauf liegt.
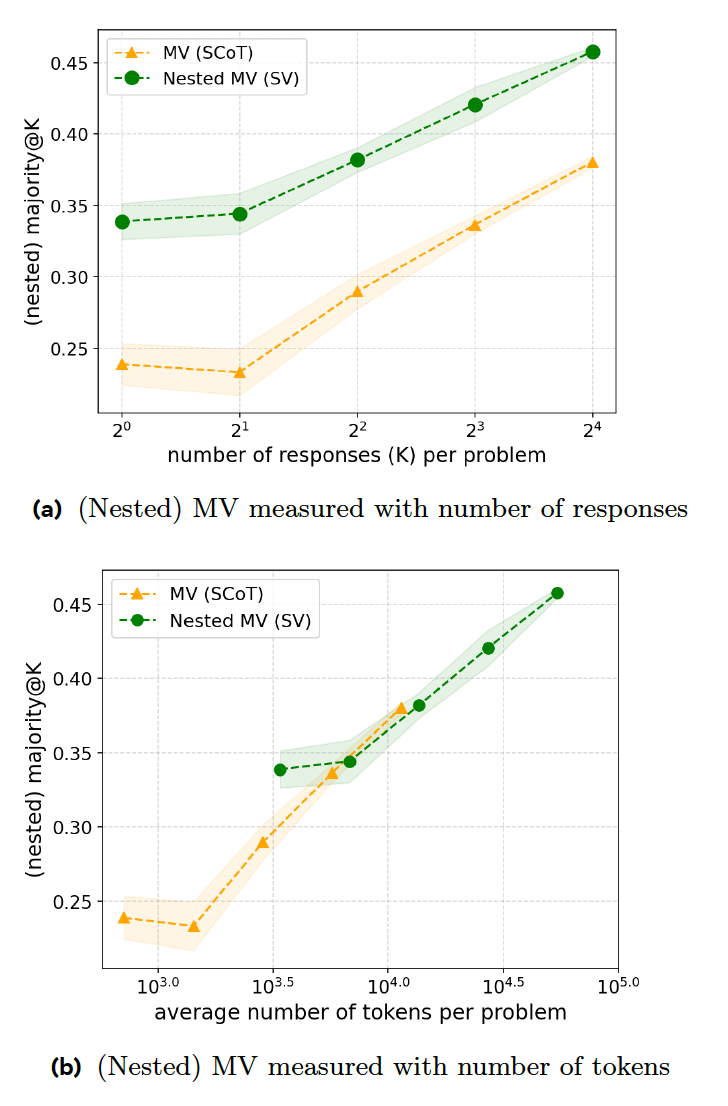
Die zweite Technik, Adaptive Sequential Voting (ASV), verbessert SV, indem sie das Modell dazu zwingt, das Problem zu untersuchen und nur dann mehrere Antworten zu generieren, wenn das Problem schwierig ist. Bei einfachen Problemen (wie etwa einer 1+1-Behauptung) generiert das Modell einfach eine einzige Antwort, ohne den Abstimmungsprozess zu durchlaufen. Dadurch wird das Modell bei der Bearbeitung sowohl einfacher als auch komplexer Probleme effizienter.
Verstärkungslernen
Während sowohl SV- als auch ASV-Techniken die Effizienz des Modells verbessern, erfordern sie eine große Menge manuell gekennzeichneter Daten. Um dieses Problem zu mildern, schlagen die Forscher „Inference Budget-Constrained Policy Optimization“ (IBPO) vor, einen Verstärkungslernalgorithmus, der dem Modell beibringt, die Länge der Argumentationspfade basierend auf der Abfrageschwierigkeit anzupassen.
IBPO ist so konzipiert, dass große Sprachmodelle (LLMs) ihre Antworten verbessern können, ohne dabei die Beschränkungen des Inferenzbudgets zu überschreiten. Der Algorithmus des bestärkenden Lernens ermöglicht es dem Modell, die durch das Training mit manuell gekennzeichneten Daten erzielten Gewinne zu übertreffen, indem kontinuierlich ASV-Trajektorien generiert, Antworten ausgewertet und Ergebnisse ausgewählt werden, die die richtige Antwort und das optimale Inferenzbudget liefern.
Ihre Experimente zeigen, dass IBPO die Pareto-Front verbessert, was bedeutet, dass ein auf IBPO trainiertes Modell bei einem festen Inferenzbudget andere Basislinien übertrifft.
Diese Erkenntnisse fallen in eine Zeit der Warnungen von Forschern, dass aktuelle KI-Modelle Probleme haben. Während Unternehmen Schwierigkeiten haben, qualitativ hochwertige Trainingsdaten zu finden und alternative Möglichkeiten zur Verbesserung ihrer Modelle zu erkunden.
Eine vielversprechende Lösung ist das bestärkende Lernen, bei dem dem Modell ein Ziel vorgegeben wird und es seine eigenen Lösungen finden kann. Im Gegensatz dazu wird das Modell beim überwachten Feintuning (Supervised Fine-Tuning, SFT) anhand von manuell markierten Beispielen trainiert.
Überraschenderweise findet das Modell oft Lösungen, an die Menschen nicht gedacht haben. Dies ist eine Formel, die bei DeepSeek-R1 funktioniert zu haben scheint, das die Dominanz amerikanischer KI-Labore in Frage stellte.
Die Forscher weisen darauf hin, dass „promptbasierte Methoden und SFT Schwierigkeiten mit absoluter Optimierung und Effizienz haben, was die Vermutung stützt, dass SFT allein keine selbstkorrigierenden Fähigkeiten ermöglicht. Diese Beobachtung wird auch durch parallele Arbeiten gestützt, die darauf hindeuten, dass dieses selbstkorrigierende Verhalten während des RL spontan auftritt und nicht manuell durch Prompts oder SFT erzeugt wird.“
Kommentarfunktion ist geschlossen.