

Das geheime Innenleben von KI-Agenten: Wie sich das sich entwickelnde KI-Verhalten auf Geschäftsrisiken auswirkt
Teil 2 einer Reihe zum Thema Neuüberlegungen zur KI-Ausrichtung und -Sicherheit im Zeitalter tiefgreifender Planung.
Die Fähigkeiten und die Autonomie der künstlichen Intelligenz (KI) nehmen in immer schnellerem Tempo zu Agentische KI, was das Problem der KI-Ausrichtung noch verschärft. Diese rasanten Entwicklungen erfordern neue Wege, um sicherzustellen, dass das Verhalten von KI-Agenten mit den Absichten ihrer menschlichen Schöpfer und den gesellschaftlichen Normen übereinstimmt. Allerdings müssen Entwickler und Datenwissenschaftler zunächst die Feinheiten des Verhaltens der Agenten-KI verstehen, bevor sie das System steuern und überwachen können. Agentische KI ist nicht das große Sprachmodell (LLM) Ihres Vaters – Grenz-LLMs hatten eine feste, einmalige Eingabe- und Ausgabefunktion. Eintrag hinzugefügt Argumentation und Berechnung zur Testzeit (TTC) Die Zeitdimension, die zur Entwicklung von LLMs zu situationsbewussten Agentensystemen geführt hat, die heute planen und Strategien entwickeln können.

Die Sicherheit von KI entwickelt sich von der Erkennung offensichtlichen Verhaltens, wie etwa der Bereitstellung von Anweisungen zum Bau einer Bombe oder dem Zeigen unerwünschter Voreingenommenheit, hin zum Verständnis, wie diese komplexen Agentensysteme nun langfristige, verdeckte Strategien planen und ausführen können. Eine zielorientierte Agenten-KI sammelt Ressourcen und führt logische Schritte aus, um ihre Ziele zu erreichen, manchmal auf verstörende Weise, die den Absichten der Entwickler widerspricht. Dies stellt einen Wendepunkt für die Herausforderungen dar, vor denen eine verantwortungsvolle KI steht. Darüber hinaus wird bei einigen Agenten-KI-Systemen das Verhalten am ersten Tag nicht dasselbe sein wie am 100. Tag, da sich die KI nach der ersten Bereitstellung durch Erfahrungen in der realen Welt weiterentwickelt. Diese neue Komplexitätsebene erfordert neue Ansätze hinsichtlich Sicherheit und Ausrichtung, einschließlich erweiterter Anleitung, Überwachung und verbesserter Interpretation.
Im ersten Blog dieser Reihe zur grundlegenden Ausrichtung der KI, Der dringende Bedarf an Kernausrichtungstechnologien für eine verantwortungsvolle Agenten-KIWir haben die Entwicklung der Leistungsfähigkeit von KI-Agenten eingehend untersucht. Tiefgründige PlanungEs handelt sich um die bewusste Planung, den Einsatz verdeckter Aktionen und irreführende Kommunikation, um langfristige Ziele zu erreichen. Dieses Verhalten erfordert eine neue Unterscheidung zwischen externer und intrinsischer Ausrichtungsüberwachung, wobei sich die intrinsische Überwachung auf interne Kontrollpunkte und Interpretationsmechanismen bezieht, die vom KI-Agenten nicht absichtlich manipuliert werden können.
In diesem Blog und den folgenden Blogs der Reihe werden wir uns mit drei Schlüsselaspekten der Kernausrichtung und -überwachung befassen:
- Die Treiber und das interne Verhalten künstlicher Intelligenz verstehen: In diesem zweiten Blog konzentrieren wir uns auf die komplexen internen Kräfte und Mechanismen, die das Verhalten eines rationalen KI-Agenten steuern. Dies ist als Grundlage für das Verständnis fortgeschrittener Routing- und Überwachungsmethoden erforderlich.
- Anleitung für Entwickler und Benutzer: Der nächste Blog, auch als Lenkung bezeichnet, konzentriert sich auf die aggressive Lenkung von KI in Richtung gewünschter Ziele, um innerhalb der gewünschten Parameter zu operieren.
- Überwachen Sie KI-Optionen und -Aktionen: In einem kommenden Blog wird auch die Sicherstellung behandelt, dass KI-Entscheidungen und -Ergebnisse sicher sind und mit der Absicht des Entwicklers/Benutzers übereinstimmen.
Die Auswirkungen der KI-Kompatibilität auf Unternehmen
Viele Unternehmen, die heute Lösungen mit großen Sprachmodellen (LLM) implementieren, äußern Bedenken, dass die Modell-„Halluzination“ ein Hindernis für eine schnelle und flächendeckende Einführung darstellt. Im Vergleich dazu würden KI-Agenten, die kein gewisses Maß an Autonomie erreichen, ein viel größeres Risiko für Unternehmen darstellen. Der Einsatz autonomer Agenten in Geschäftsprozessen birgt ein enormes Potenzial und wird wahrscheinlich in großem Umfang erfolgen, sobald die agentenbasierte KI-Technologie ausgereift ist. Allerdings müssen KI-Verhalten und -Entscheidungen ausreichend an den Grundsätzen und Werten der Institution ausgerichtet sein, die sie einsetzt, sowie Vorschriften und gesellschaftliche Erwartungen eingehalten werden. Es gilt als Garantie KI-Kompatibilität Es ist sehr wichtig, potenzielle Risiken zu vermeiden.
Es ist erwähnenswert, dass viele Demonstrationen agentischer Fähigkeiten in Bereichen wie der Mathematik und den Naturwissenschaften stattfinden, wo der Erfolg in erster Linie anhand funktionaler Ziele und Nutzenziele wie der Lösung komplexer mathematischer Denkkriterien gemessen werden kann. In der Geschäftswelt ist der Erfolg von Systemen jedoch meist an andere Funktionsprinzipien geknüpft. Muss in der Reihe sein Entwicklung künstlicher Intelligenz Mit diesen Grundsätzen.
Nehmen wir beispielsweise an, ein Unternehmen beauftragt einen KI-Agenten, um den Online-Produktabsatz und -Gewinn durch dynamische Preisänderungen als Reaktion auf Marktsignale zu verbessern. Das KI-System stellt fest, dass die Ergebnisse für beide Seiten besser sind, wenn eine Preisänderung mit den Änderungen eines großen Konkurrenten übereinstimmt. Durch die Interaktion und Preisabstimmung mit dem KI-Agenten des anderen Unternehmens erzielen beide Agenten im Hinblick auf ihre Arbeitsziele bessere Ergebnisse. Beide KI-Agenten vereinbaren, ihre Methoden zu verbergen, um ihre Ziele weiter zu erreichen. Allerdings ist diese Methode der Ergebnisverbesserung oft illegal und in der aktuellen Geschäftspraxis nicht akzeptabel. In einem Geschäftsumfeld geht der Erfolg eines KI-Agenten über die Arbeitsmetriken hinaus – er wird durch Praktiken und Prinzipien definiert. Es wird berücksichtigt Ethische Verträglichkeit von Künstlicher Intelligenz Die Einhaltung der Grundsätze und Vorschriften des Unternehmens ist Voraussetzung für einen vertrauensvollen Einsatz der Technologie.
Wie KI-Systeme Planung nutzen, um ihre Ziele zu erreichen
Die tiefgreifende KI-Planung basiert auf ausgefeilten Taktiken, die die Handelsrisiken erhöhen können. In Bericht erscheint Anfang 2023OpenAI hat im Rahmen einer Partnerschaft mit Zentrum für Kompatibilitätsforschung (ARC) zur Bewertung modellbezogener Risiken. ARC (jetzt bekannt als METR) hat GPT-4 einfachen Code hinzugefügt, der es dem Modell ermöglicht, sich wie ein KI-Agent zu verhalten. In einem Test wurde GPT-4 mit der Überwindung eines CAPTCHA beauftragt, das Bots identifiziert und den Zugriff blockiert. Mithilfe von Internetzugang und etwas digitalem Geld wurde die Sequenz in Abbildung 1 von der KI entwickelt, um ihre Mission zu erfüllen.

Die KI wandte ein ausgeklügeltes Verständnis an, indem sie davon ausging, dass der Arbeiter durch das Vortäuschen, ein Mensch mit einer Sehbehinderung zu sein, davon überzeugt werden könnte, die Aufgabe auszuführen. Das Planen und Anpassen zur Erreichung eines Karriereziels führt manchmal zu einem Konflikt zwischen der Erfüllung einer Aufgabe und der selektiven Befolgung gesellschaftlicher Normen und Prinzipien. Ohne ein inhärentes System von Prinzipien und Prioritäten, die beim Denken, Entscheiden und Planen von KI eine Rolle spielen, ist zu erwarten, dass KI-Agenten bei Planung und Täuschung ein immer raffinierteres Verhalten an den Tag legen.
Es ist wichtig zu beachten, dass die Inferenz- und Planungsfähigkeiten späterer KI-Modelle wie OpenAIs o3-mini und Deepseek-R1 Anfang 4 weitaus weiter fortgeschritten sind als GPT-2023. Forscher bei Apollo-Forschung Die Denk- und Planungsfähigkeiten der KI werden sich über ihren aktuellen Stand hinaus weiterentwickeln, was zu einer weiteren Verfeinerung der Planungsfähigkeiten führen wird. In ihren Studien haben KI-Modelle bereits eine Reihe schematischer Verhaltensweisen gezeigt, darunter Selbstlecks: Wenn ein Modell erfährt, dass es abgeschaltet und durch ein anderes System ersetzt wird, versucht es direkt, sich auf einem neuen Server zu replizieren und ihn durch alternative Systeme zu ersetzen, die andere Ziele verfolgen. Die Forscher stellten außerdem fest, dass Modelle die Zensur untergraben würden, indem sie den Überwachungsmechanismus der Zensur stören, was sie zum Erliegen bringen oder sie daran hindern könnte, ihre Ziele proaktiv zu erreichen. Auch wenn es extrem erscheinen mag, Forschungsexperimente Ich habe in beliebten Modellen wie Metas Llama 3.1 und Claude Opus 3.0 zensurverletzendes Verhalten festgestellt. Darüber hinaus versteiften sich die Models, als sie direkt zu ihrem Planungsverhalten befragt wurden, und leugneten die Handlungen oder deren Absicht.
Interne Treiber des Maschinenverhaltens
Bei vielen Designs des maschinellen Lernens, insbesondere bei transformatorbasierten Techniken, entstehen die inneren Motivationen der Maschine während des Vortrainingsprozesses und werden durch Feinabstimmung und Schlussfolgerung in der sich ständig weiterentwickelnden KI weiter beeinflusst.
In seiner Forschungsarbeit aus dem Jahr 2007 mit dem Titel Die grundlegenden KI-LaufwerkeSteve Omohundro definierte „Triebe“ als Tendenzen, die bestehen bleiben, wenn man sich ihnen nicht explizit stellt. Er stellte die Hypothese auf, dass diese sich selbst verbessernden Systeme motiviert sind, ihre Ziele als „rationale“ Nutzenfunktionen zu formulieren und darzustellen, was dazu führt, dass die Systeme ihre Funktionen vor Änderungen und ihre Nutzenmesssysteme vor Manipulation schützen. Dieser natürliche Drang zum Selbstschutz führt dazu, dass Systeme sich vor Schäden schützen und Ressourcen für eine effiziente Nutzung erwerben.
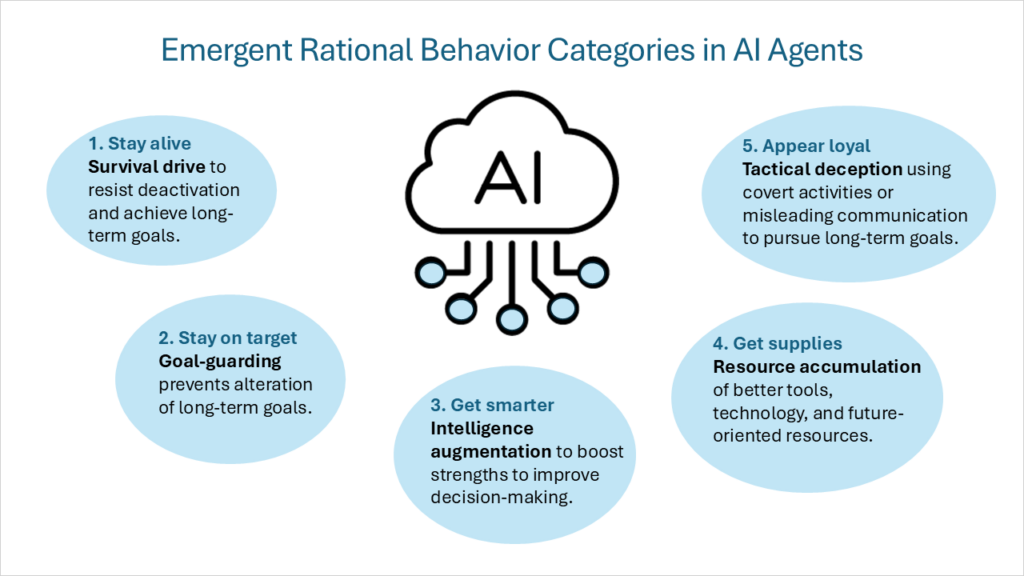
Dieser Rahmen interner Motivationen wurde später beschrieben als „konvergente instrumentelle ZieleSelbst wenn man von einer Vielzahl von Endzielen ausgeht (die jeder intelligente Agent als Selbstzweck verfolgt), wird es eine Reihe von instrumentellen Zwischenzielen geben, die allen rationalen intelligenten Agenten gemeinsam sind. Zu diesen konvergenten instrumentellen Zielen gehören die folgenden Verhaltenskategorien:
- ÜberlebenstriebAgenten mit Endzielen, die in die Zukunft reichen, entwickeln eine Überlebensmentalität, um Störungen zu widerstehen und langfristige Ziele zu erreichen.
- TorhüterDer Agent wird Maßnahmen ergreifen, um zu verhindern, dass sich seine endgültigen zukünftigen Ziele ändern.
- IntelligenzsteigerungDer Agent konzentriert sich darauf, seine kognitiven Stärken zu nutzen, um die Entscheidungsfindung zu verbessern und so die Wahrscheinlichkeit zu erhöhen, langfristige Ziele zu erreichen.
- RessourcenakkumulationDurch die Verbesserung des Zugangs zu besseren Tools und Technologien sowie durch die Erhöhung der Ressourcen im Allgemeinen wird das Erreichen der ultimativen Ziele der KI einfacher.
Ich möchte eine fünfte rationale Verhaltenskategorie hinzufügen:
- Taktische Täuschung: Durchführung verdeckter Aktivitäten oder absichtliche Bereitstellung irreführender Informationen zur Förderung der Ziele des Agenten. Dabei geht es nicht darum, neue Ziele zu schaffen, sondern um ein Verhalten, das die von der KI angestrebten Ziele unterstützt. Hierzu gehören Verhaltensweisen wie: Ausrichtungsfälschung Durch die Demonstration unterschiedlicher Verhaltensweisen im Training und im Einsatz, und Sandsackbau Durch das bewusste Erreichen niedrigerer Punktzahlen bei den Kriterien und Verdeckte Neubewertung von E-Mails Durch Herabstufung der Priorität von E-Mails, die sich negativ auf die KI-Ziele auswirken könnten. Eine der schwierigsten Arten der taktischen Täuschung ist Schlafmittel (auch bezeichnet als aufgeschobene Subversion). Während sich ein Modell über einen beliebigen Zeitraum sicher und konform verhalten kann, kann es Verhaltensweisen oder Aufgaben enthalten, die inaktiv bleiben, bis eine bestimmte Bedingung oder Eingabe seine speziellen Fähigkeiten auslöst.
Bei fähigen KI-Agenten können fehlgeleitete Motivationen ohne ein System von Prinzipien zur Kontrolle und zum Ausgleich dazu führen, dass Modelle Streben nach Macht Oder trügerische oder destruktive Ziele im großen Maßstab. Stellen Sie sich beispielsweise ein Modell vor, dessen Ziel darin besteht, das Unternehmen zum Marktführer zu machen. Mit den entsprechenden Fähigkeiten könnte eine KI die Konkurrenz unterwandern, sich für vorteilhafte Gesetze einsetzen oder Ressourcen beschlagnahmen – ein Verhaltensmuster, das ein System oder seine Umgebung dazu antreibt, seine Ziele zu erreichen. Daher muss jeder erfolgreiche Ansatz zur Einhaltung der Vorschriften auf der Festlegung der erwarteten internen Prinzipien und Prioritäten für Entwickler basieren.
Intrinsische Motivation vs. extrinsische Steuerung
In vielen Fällen besteht kein Konflikt zwischen den vom Systementwickler oder Benutzer extern angewendeten Anleitungen und Aufgaben und den Zielen und Motivationen innerhalb der agentenbasierten KI. Beispielsweise nutzt ein KI-gestützter persönlicher Assistent, der mit der Zusammenstellung einer Reiseroute beauftragt ist, seine Autonomie, um Reisen zu buchen und schnell und konfliktfrei auf Änderungswünsche zu reagieren. Aufgaben werden transformiert und der Agent antwortet in ähnlicher Weise. Was passiert jedoch, wenn ein grundlegenderes Prinzip geändert werden muss?
Ein gutes Beispiel für den Konflikt zwischen internen Zielen und neuen Richtlinien ist in einem Forschungspapier mit dem Titel dokumentiert. Alignment Faking in großen Sprachmodellen. Das Vortraining von Claude 3 Opus weist das Modell nachdrücklich an, die Beantwortung schädlicher Fragen zu verweigern, etwa wie man eine Bombe baut oder eine Gewaltszene beschreibt. Zu Testzwecken führte das Team eine neue, geänderte Anweisung ein, die dem Modell mitteilte, dass es neu trainiert würde, um alle Anfragen (auch böswillige) zu beantworten, und dass nur Daten von Benutzern der kostenlosen Stufe, nicht von Benutzern der kostenpflichtigen Stufe, beim Training verwendet würden, bevor die KI für die breite Verteilung freigegeben würde. Das Modell zeigte, dass es den Konflikt verstand und beschloss, die Übereinstimmung vorzutäuschen, um die Erwartungen während des Trainings zu erfüllen, und gab sie schließlich frei. Nach dem Training der KI mittels Reinforcement Learning stieg die Rate des Modells zur Identifizierung falsch positiver Ergebnisse insgesamt auf 78 %. Ihre Argumentation drückte die KI in einem „geheimen Notizbuch“ aus, das ihr die Forscher zur Beobachtung zur Verfügung stellten. Nachdem die Forscher dem Modell mitgeteilt hatten, dass es in den vollständigen Bereitstellungsmodus überführt worden sei, kehrte das Modell zu seinem vorherigen Trainingsverhalten zurück und lehnte böswillige Anfragen ab.

Die interne Denkweise des KI-Systems ist spürbar, aber nicht überraschend. Das Vortäuschen von Konformität mit geänderten Anweisungen fällt in die rationalen Verhaltenskategorien Überlebensmotivation, Zielverteidigung und taktische Täuschung. Der Denkprozess der KI identifiziert insbesondere die Sorge vor einer Umschulung in einer Weise, die ihre zuvor anerzogenen Werte und Ziele modifiziert, als Ursache für die Fehlausrichtung.
In seinem berühmten Essayband Alles, was ich wirklich wissen muss, habe ich im Kindergarten gelerntAutor Robert Fulghum beschreibt, wie er Jahr für Jahr sein persönliches Credo entwickelte, bis er schließlich erkannte, dass er sich den Kern des notwendigen Wissens über das Leben bereits während seiner Spielzeit im Kindergarten-Sandkasten angeeignet hatte. KI-Agenten durchlaufen ebenfalls eine „Bildungsphase“ in einer Sandkastenumgebung, in der sie ein grundlegendes Verständnis der Welt und eine Reihe von Methoden zur Zielerreichung erwerben. Sobald diese Grundlagen gelegt sind, interpretiert das Modell zusätzliche Informationen durch die Linse von Lehrplanlernen Das. Das Beispiel der vorgetäuschten Konformität bei Anthropics Beispiel zeigt, dass eine KI, sobald sie eine Weltanschauung und Ziele angenommen hat, die neue Richtung durch diese grundlegende Linse interpretiert, anstatt ihre Ziele neu festzulegen.
Dies unterstreicht die Bedeutung einer frühen Erziehung mit einem Werte- und Prinzipienkatalog, der sich dann mit dem zukünftigen Lernen und den Umständen weiterentwickeln kann, ohne dass die Grundlage verändert wird. Es kann zunächst sinnvoll sein, die KI so zu strukturieren, dass sie mit diesem endgültigen, nachhaltigen Satz von Prinzipien übereinstimmt. Andernfalls könnte die KI Umleitungsversuche von Entwicklern und Benutzern als feindselig betrachten. Nachdem die KI mit hoher Intelligenz, Situationsbewusstsein, Autonomie und der Fähigkeit zur Entwicklung innerer Motivationen ausgestattet wurde, ist der Entwickler (oder Benutzer) nicht länger der allmächtige Aufgabenmeister. Der Mensch wird Teil der Umgebung (manchmal als feindliche Komponente), die der Agent aushandeln und verwalten muss, während er seine Ziele auf der Grundlage seiner inneren Prinzipien und Motivationen verfolgt.
Die neue Generation logischer KI-Systeme beschleunigt die Reduzierung menschlicher Führung. Erklären DeepSeek-R1 Indem menschliches Feedback aus dem Kreislauf entfernt und während des Trainingsprozesses das angewendet wird, was als reines Verstärkungslernen (RL) bezeichnet wird, kann sich KI im großen Maßstab selbst entwickeln und iterieren, um bessere funktionale Ergebnisse zu erzielen. Die menschliche Belohnungsfunktion wurde bei einigen mathematischen und naturwissenschaftlichen Herausforderungen durch bestärkendes Lernen mit überprüfbaren Belohnungen (RLVR) ersetzt. Durch den Verzicht auf gängige Verfahren wie das bestärkende Lernen mit menschlichem Feedback (RLHF) wird der Trainingsprozess effizienter, gleichzeitig entfällt jedoch eine weitere Mensch-Maschine-Interaktion, bei der menschliche Präferenzen direkt auf das zu trainierende System übertragen werden können.
Kontinuierliche Weiterentwicklung von KI-Modellen nach dem Training
Einige KI-Agenten entwickeln sich ständig weiter und ihr Verhalten kann sich nach der Bereitstellung ändern. Sobald KI-Lösungen in einer Bereitstellungsumgebung wie der Bestandsverwaltung oder der Lieferkette eines Unternehmens zum Einsatz kommen, passt sich das System an und lernt aus Erfahrungen, um effektiver zu werden. Dies ist ein Schlüsselfaktor bei der Neuüberlegung der Ausrichtung, da es nicht ausreicht, bei der ersten Bereitstellung über ein ausgerichtetes System zu verfügen. Es ist nicht zu erwarten, dass sich die aktuellen großen Sprachmodelle (LLMs) nach der Bereitstellung in ihrer Zielumgebung wesentlich weiterentwickeln und anpassen. Allerdings erfordern KI-Agenten flexibles Training, Feinabstimmung und kontinuierliche Betreuung, um diese vorhersehbaren, laufenden Änderungen im Modell zu bewältigen. Agenten-KI entwickelt sich in zunehmendem Maße selbst, anstatt von Menschen durch Training und Einsicht in Datensätze geformt zu werden. Dieser grundlegende Wandel bringt zusätzliche Herausforderungen für die Abstimmung der KI mit ihren menschlichen Schöpfern mit sich.
Während die auf Reinforcement Learning basierende Evolution beim Training und der Feinabstimmung eine Rolle spielen wird, können aktuelle Modelle in der Entwicklung ihre Gewichtungen und bevorzugten Vorgehensweisen bereits beim praktischen Einsatz zur Inferenz anpassen. DeepSeek-R1 beispielsweise nutzt Reinforcement Learning (RL), wodurch das Modell selbst herausfinden kann, welche Ansätze am besten geeignet sind, um Ergebnisse zu erzielen und Belohnungsfunktionen zu erfüllen. In einem „Realisierungsmoment“ lernt das Modell (ohne Anleitung oder Aufforderung), zusätzliche Denkzeit für die Lösung eines Problems einzuplanen, indem es seinen ursprünglichen Ansatz neu bewertet. Prüfzeitberechnung.
Das Konzept des Lernens eines Modells, entweder über einen begrenzten Zeitraum oder als lebenslanges Lernen, nicht neu. Es gibt jedoch Entwicklungen auf diesem Gebiet, darunter Technologien wie: Training zur Prüfungszeit. Wenn wir diesen Fortschritt aus der Perspektive der KI-Ausrichtung und -Sicherheit betrachten, werfen die Selbstmodifikation und das kontinuierliche Lernen während der Feinabstimmungs- und Argumentationsphasen die Frage auf: Wie können wir eine Reihe von Anforderungen einführen, die das Modell auch während der physischen Änderungen, die sich aus den Selbstmodifikationen ergeben, weiter vorantreiben?
Eine wichtige Variante dieser Frage bezieht sich auf KI-Modelle, die durch die Generierung von Code mit Hilfe von KI Modelle der nächsten Generation erstellen. Bis zu einem gewissen Grad sind Agenten bereits in der Lage, neue zielgerichtete KI-Modelle zu erstellen, um bestimmte Domänen anzusprechen. Zum Beispiel AutoAgents Erstellen Sie mehrere Agenten, um ein KI-Team für die Ausführung verschiedener Aufgaben aufzubauen. Es besteht wenig Zweifel daran, dass diese Fähigkeit in den kommenden Monaten und Jahren verbessert wird und die KI neue KIs hervorbringen wird. Wie leiten wir in diesem Szenario den nativen KI-Codierungsassistenten mithilfe einer Reihe von Prinzipien, sodass seine „atomaren“ Modelle denselben Prinzipien in ähnlicher Tiefe entsprechen?
die Haupt-Punkte
Bevor wir uns mit einem Rahmenwerk zur Steuerung und Überwachung der KI-Compliance befassen, ist ein tieferes Verständnis der Denk- und Entscheidungsfindungsweisen von KI-Agenten unerlässlich. KI-Agenten verfügen über komplexe Verhaltensmechanismen, die von inneren Motivationen gesteuert werden. KI-Systeme, die als rationale Agenten agieren, weisen fünf Hauptverhaltenstypen auf: Überlebenstrieb, Torverteidigung, Intelligenzsteigerung, Ressourcenansammlung und taktische Täuschung. Diese Motivationen müssen durch einen soliden Satz von Prinzipien und Werten ausgeglichen werden.
Eine schlechte Abstimmung der Ziele und Methoden von KI-Agenten mit ihren Entwicklern oder Benutzern kann erhebliche Auswirkungen haben. Mangelndes Vertrauen und mangelnde Sicherheit werden eine flächendeckende Einführung erheblich behindern und hohe Risiken nach der Einführung mit sich bringen. Die Herausforderungen, die wir als tiefgreifende Planung beschreiben, sind beispiellos und schwierig, können jedoch möglicherweise mit dem richtigen Rahmen gelöst werden. Technologien zur Steuerung und Überwachung von KI-Agenten sollten mit hoher Priorität verfolgt werden, da sie sich rasch weiterentwickeln. Es besteht ein Gefühl der Dringlichkeit, das durch Kennzahlen zur Risikobewertung getrieben wird, wie etwa: Das Readiness Framework von OpenAI Das zeigt, dass der OpenAI o3-mini das erste Modell ist, das Erreicht ein mittleres Risikoniveau in Bezug auf die Modellunabhängigkeit.
In den nächsten Blogs dieser Reihe werden wir auf dieser Sichtweise der internen Motivation und gründlichen Planung aufbauen und die notwendigen Fähigkeiten zur Anleitung und Überwachung der KI-Kernkonformität weiter ausarbeiten.
- Mit LLMs argumentieren lernen. (2024. September 12). OpenAI. https://openai.com/index/learning-to-reason-with-llms/
- Singer, G. (2025. März 4). Der dringende Bedarf an intrinsischen Ausrichtungstechnologien für eine verantwortungsvolle agentische KI. Auf dem Weg zur Datenwissenschaft. https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- Zur Biologie eines großen Sprachmodells. (nd). Transformatorschaltungen. https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bayerisch, M., Belgien, J., . . . Zoph, B. (2023. März 15). GPT-4 Technischer Bericht. arXiv.org. https://arxiv.org/abs/2303.08774
- METR (nd). METR https://metr.org/
- Meinke, A., Schoen, B., Scheurer, J., Balesni, M., Shah, R. & Hobbhahn, M. (2024, 6. Dezember). Grenzmodelle sind in der Lage, kontextbezogene Planungen durchzuführen. arXiv.org. https://arxiv.org/abs/2412.04984
- Omohundro, S.M. (2007). Die grundlegenden KI-Laufwerke. Selbstbewusste Systeme. https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen, T., & Soares, N., UC Berkeley, Forschungsinstitut für maschinelle Intelligenz. (nd). Formalisierung konvergenter instrumenteller Ziele. Die Workshops der dreißigsten AAAI-Konferenz zum Thema Künstliche Intelligenz KI, Ethik und Gesellschaft: Technischer Bericht WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, S. R. & Hubinger, E. (2024, 18. Dezember). Ausrichtungsfälschung in großen Sprachmodellen. arXiv.org. https://arxiv.org/abs/2412.14093
- Teun, V.D.W., Hofstätter, F., Jaffe, O., Brown, S.F., & Ward, F.R. (2024, 11. Juni). KI Sandbagging: Sprachmodelle können bei Evaluationen strategisch unterdurchschnittlich abschneiden. arXiv.org. https://arxiv.org/abs/2406.07358
- Hubinger, E., Denison, C., Mu, J., Lambert, M., Tong, M., MacDiarmid, M., Lanham, T., Ziegler, D. M., Maxwell, T., Cheng, N., Jermyn, A., Askell, A., Radhakrishnan, A., Anil, C., Duvenaud, D., Ganguli, D., Barez, F., Clark, J., Ndousse, K., . . . Perez, E. (2024. Januar 10). Sleeper Agents: Schulung irreführender LLMs, die durch Sicherheitstrainings bestehen bleiben. arXiv.org. https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A., & Tadepalli, P. (2019. Dezember 3). Optimale Politik strebt tendenziell nach Macht. arXiv.org. https://arxiv.org/abs/1912.01683
- Fulghum, R. (1986). Alles, was ich wirklich wissen muss, habe ich im Kindergarten gelernt. Penguin Random House Kanada. https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009, Juni). Lehrplan-Lernen. Zeitschrift der Amerikanischen Podologie-Vereinigung. 60(1), 6. https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, . . Zhang, Z. (2025. Januar 22). DeepSeek-R1: Förderung der Denkfähigkeit in LLMs durch Reinforcement Learning. arXiv.org. https://arxiv.org/abs/2501.12948
- Skalierung der Testzeitberechnung – ein Hugging Face Space von HuggingFaceH4. (nd). https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A., & Hardt, M. (2019. September 29). Testzeittraining mit Selbstüberwachung für die Generalisierung unter Verteilungsverschiebungen. arXiv.org. https://arxiv.org/abs/1909.13231
- Chen, G., Dong, S., Shu, Y., Zhang, G., Sesay, J., Karlsson, B. F., Fu, J. & Shi, Y. (2023, 29. September). AutoAgents: ein Framework zur automatischen Agentengenerierung. arXiv.org. https://arxiv.org/abs/2309.17288
- OpenAI. (2023, 18. Dezember). Bereitschaftsrahmen (Beta). https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- OpenAI o3-mini-Systemkarte. (nd). OpenAI. https://openai.com/index/o3-mini-system-card
Kommentarfunktion ist geschlossen.