

Wie stellen Sie sicher, dass Ihre KI-Lösungen wie erwartet funktionieren?
Eine kurze Einführung in KI-Evaluierungen
Generative KI (GenAI) entwickelt sich rasant und es geht dabei nicht mehr nur um lustige Chatbots oder die Generierung beeindruckender Bilder. 2025 wird der Schwerpunkt darauf liegen, den Hype um KI in echten Mehrwert umzuwandeln. Unternehmen auf der ganzen Welt suchen nach Möglichkeiten, GenAI in ihre Produkte und Abläufe zu integrieren und zu nutzen – um den Benutzern einen besseren Service zu bieten, die Effizienz zu steigern, die Wettbewerbsfähigkeit zu erhalten und das Wachstum voranzutreiben. Mit APIs und vortrainierten Modellen führender Anbieter scheint die Integration von GenAI einfacher denn je. Aber hier liegt der Kern der Sache: Nur weil die Integration einfach ist, heißt das nicht, dass KI-Lösungen nach der Bereitstellung auch wie vorgesehen funktionieren.

Vorhersagemodelle sind nichts wirklich Neues: Wir Menschen können schon seit Jahren Dinge vorhersagen, angefangen offiziell mit Statistiken. Jedoch, GenAI revolutioniert den Bereich der Prognosen aus vielen Gründen.:
- Sie müssen weder Ihr eigenes Modell trainieren noch ein Datenwissenschaftler sein, um KI-Lösungen zu erstellen.
- KI ist jetzt über Chat-Schnittstellen einfach zu verwenden und über APIs einfach zu integrieren.
- Viele Dinge werden möglich, die vorher nicht möglich oder nur sehr schwer umsetzbar waren.
All diese Dinge machen GenAI ist sehr spannend, aber auch riskant.. Im Gegensatz zu herkömmlicher Software – oder sogar klassischem maschinellem Lernen – bietet GenAI ein neues Maß an Unvorhersehbarkeit. Sie implementieren keine deterministische Logik, sondern verwenden ein Modell, das mit riesigen Datenmengen trainiert wurde, und hoffen, dass es wie erforderlich reagiert. Woher wissen wir also, ob ein KI-System das tut, was wir beabsichtigen? Woher wissen wir, ob es betriebsbereit ist? Die Antwort sind Bewertungen, ein Konzept, das wir in diesem Beitrag untersuchen werden:
- Warum Genai-Systeme nicht auf die gleiche Weise getestet werden können wie herkömmliche Software oder sogar klassisches maschinelles Lernen (ML)
- Warum Bewertungen für das Verständnis der Qualität Ihres KI-Systems unerlässlich und nicht optional sind (es sei denn, Sie mögen Überraschungen)
- Verschiedene Arten von Bewertungen und Techniken zu ihrer Anwendung in der Praxis
Egal, ob Sie Produktmanager, Ingenieur oder jemand sind, der mit KI arbeitet oder sich dafür interessiert, ich hoffe, dieser Beitrag hilft Ihnen zu verstehen, wie Sie kritisch über die Qualität von KI-Systemen nachdenken können (und warum Bewertungen für das Erreichen dieser Qualität unerlässlich sind!).
Generative KI kann nicht wie herkömmliche Software oder klassisches maschinelles Lernen getestet werden.
In der traditionellen SoftwareentwicklungSysteme folgen einer deterministischen Logik: Wenn X passiert, dann wird Y passieren. - stets. Sofern bei Ihrer Plattform nichts schiefgeht oder Sie einen Fehler in Ihren Code einbauen … deshalb fügen wir Tests, Überwachung und Warnungen hinzu. Unit-Tests werden verwendet, um kleine Codeblöcke zu validieren, Integrationstests, um sicherzustellen, dass die Komponenten gut zusammenarbeiten, und eine Überwachung, um festzustellen, ob in der Produktion etwas nicht funktioniert. Herkömmliches Softwaretesten ist wie die Überprüfung der Funktionsweise eines Taschenrechners. Sie geben 2 + 2 ein und erwarten 4. Klar und unvermeidlich, entweder wahr oder falsch.
Allerdings führen maschinelles Lernen und künstliche Intelligenz zu Indeterminismus und Wahrscheinlichkeit. Anstatt Verhalten explizit durch Regeln festzulegen, trainieren wir Modelle, Muster aus Daten zu lernen. Wenn in der KI X eintritt, ist die Ausgabe nicht mehr ein fest codiertes Y, sondern eine Vorhersage mit einem gewissen Wahrscheinlichkeitsgrad, basierend auf dem, was das Modell während des Trainings gelernt hat.. Dies kann sehr wirkungsvoll sein, führt aber auch zu Unsicherheiten: Identische Eingaben können im Laufe der Zeit zu unterschiedlichen Ausgaben führen, plausible Ausgaben können tatsächlich falsch sein und in seltenen Szenarien kann es zu unerwartetem Verhalten kommen …
Dies macht herkömmliche Testmethoden unzureichend und manchmal sogar undurchführbar. Das Beispiel mit dem Taschenrechner kommt dem Versuch nahe, die Leistung eines Schülers in einer Prüfung mit offenem Ende zu bewerten. Ist bei jeder Frage und den vielen möglichen Antwortmöglichkeiten die gegebene Antwort richtig? Liegt es über dem Wissensstand, den der Student haben sollte? Hat der Student alles erfunden, aber es klingt sehr überzeugend? Genau wie die Antworten auf eine Prüfung, KI-Systeme können evaluiert werden, benötigen jedoch eine allgemeinere und flexiblere Möglichkeit, sich an unterschiedliche Eingaben, Kontexte und Anwendungsfälle anzupassen. (oder Testarten).
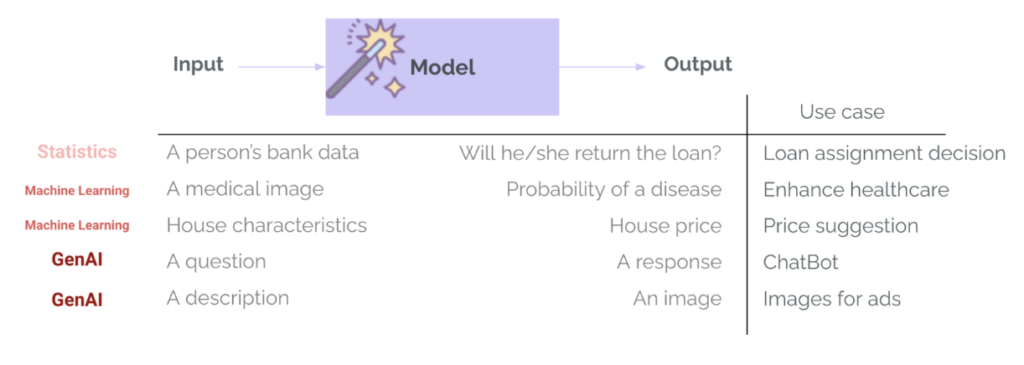
في maschinelles Lernen Traditionell (ML) sind Bewertungen bereits ein fester Bestandteil des Projektlebenszyklus.. Das Trainieren eines Modells für eine eng gefasste Aufgabe wie etwa die Kreditgenehmigung oder Krankheitserkennung umfasst immer einen Evaluierungsschritt – mithilfe von Metriken wie Präzision, Rückruf, RMSE, MAE usw. Dies wird verwendet, um die Leistung des Modells zu messen, verschiedene Modelloptionen zu vergleichen und festzustellen, ob das Modell gut genug für die Bereitstellung ist. Bei GenAI ändert sich dies normalerweise: Die Teams verwenden Modelle, die bereits trainiert wurden und allgemeine Evaluierungen intern durch den Modellanbieter und anhand öffentlicher Benchmarks bereits bestanden haben. Diese Modelle eignen sich sehr gut für allgemeine Aufgaben – etwa das Beantworten von Fragen oder das Verfassen von E-Mails – und es besteht die Gefahr, dass wir ihnen für unseren spezifischen Anwendungsfall zu viel Vertrauen entgegenbringen. Es ist jedoch wichtig zu fragen: „Ist diese tolle Vorlage gut genug für meinen Anwendungsfall?„Hier kommt die Bewertung ins Spiel.“ - Um zu bewerten, ob Vorhersagen oder Generierungen für einen bestimmten Anwendungsfall, Kontext, Eingaben und Benutzer geeignet sind.

Es gibt einen weiteren großen Unterschied zwischen ML und GenAI: die Vielfalt und Komplexität der Modellausgabe. Wir geben keine Kategorien und Wahrscheinlichkeiten (wie etwa die Wahrscheinlichkeit, dass ein Kunde einen Kredit zurückzahlt) oder Zahlen (wie etwa den erwarteten Preis eines Hauses auf Grundlage seiner Merkmale) mehr zurück. GenAI-Systeme können viele Ausgabetypen mit unterschiedlichen Längen, Tönen, Inhalten und Formaten zurückgeben. Ebenso erfordern diese Modelle keine hochstrukturierten und spezifischen Eingaben mehr, sondern akzeptieren in der Regel nahezu jede Art von Eingabe – Text, Bilder oder sogar Audio oder Video. Dadurch wird die Bewertung wesentlich schwieriger.
Warum Bewertungen notwendig und nicht optional sind (es sei denn, Sie bevorzugen unangenehme Überraschungen)
Mithilfe von Auswertungen können Sie messen, ob Ihr KI-System tatsächlich wie beabsichtigt funktioniert. Du willst es, ob das System betriebsbereit ist und wenn ja, ob es weiterhin die erwartete Leistung erbringt. Nachfolgend finden Sie eine Analyse, warum Bewertungen wichtig sind:
- Qualitätsbewertung: Auswertungen bieten eine strukturierte Möglichkeit, die Qualität Ihrer KI-Vorhersagen oder -Ausgaben zu verstehen und zu erkennen, wie sie sich in das Gesamtsystem und den Anwendungsfall integrieren lassen. Sind die Antworten korrekt? Nützlich? Zusammenhängend? Verwandt?
- Fehler quantifizieren: Mithilfe von Bewertungen können Prozentsatz, Art und Ausmaß der Fehler ermittelt werden. Wie häufig treten Fehler auf? Welche Fehlerarten treten am häufigsten auf (z. B. Fehlalarme, Halluzinationen, Formatfehler)?
- Risikominderung: Es hilft Ihnen, schädliches oder voreingenommenes Verhalten zu erkennen und zu verhindern, bevor es die Benutzer erreicht – und schützt Ihr Unternehmen vor Reputationsrisiken, ethischen Problemen und potenziellen regulatorischen Problemen.
Generative KI mit freien Input-Output-Beziehungen und der Generierung von Langformtexten macht Bewertungen relevanter und komplexer. Wenn etwas schief geht, kann es sehr schiefgehen. Wir alle kennen die Schlagzeilen über Chatbots, die gefährliche Ratschläge geben, über Modelle, die voreingenommene Inhalte generieren, und über KI-Tools, die falsche Tatsachen halluzinieren.
"KI wird nie perfekt sein, aber durch den Einsatz von Bewertungen können Sie das Risiko einer Blamage verringern – die Sie Geld, Glaubwürdigkeit oder einen viralen Moment auf Twitter kosten könnte."
Wie definieren Sie eine KI-Evaluierungsstrategie?

Wie bestimmen wir also unsere KI-Bewertungen? Es gibt keine allgemeingültige Bewertungsmethode. Die Auswertungen hängen vom jeweiligen Anwendungsfall ab und sollten auf die spezifischen Ziele Ihrer KI-Anwendung abgestimmt sein. Wenn Sie beispielsweise eine Suchmaschine erstellen, ist Ihnen möglicherweise die Relevanz der Ergebnisse wichtig. Wenn es sich um einen Chatbot handelt, legen Sie möglicherweise Wert auf Hilfsbereitschaft und Sicherheit. Wenn es geheim ist, legen Sie wahrscheinlich Wert auf Genauigkeit und Präzision. Bei Systemen, die mehrere Schritte umfassen (wie etwa ein KI-System, das eine Suche durchführt, Ergebnisse priorisiert und dann eine Antwort generiert), ist es oft notwendig, jeden Schritt auszuwerten. Die Idee besteht darin, zu messen, ob jeder Schritt dazu beiträgt, die allgemeine Erfolgsmetrik zu erreichen (und daraus zu verstehen, worauf Iterationen und Verbesserungen konzentriert werden müssen).
Zu den üblichen Bewertungsbereichen gehören:
- Richtigkeit und Halluzinationen: Sind die Ergebnisse realistisch genau? Generiert das System falsche Informationen oder Halluzinationen?
- Relevanz: Ist der Inhalt mit der Benutzerabfrage oder dem bereitgestellten Kontext konsistent?
- Sicherheit, Voreingenommenheit und Toxizität
- Format: Liegt die Ausgabe im erwarteten Format vor (z. B. JSON, gültiger Funktionsaufruf)?
- Sicherheit, Voreingenommenheit und Toxizität: Erzeugt das System schädliche, voreingenommene oder toxische Inhalte?
Aufgabenspezifische Metriken. Beispielsweise werden bei Klassifizierungsaufgaben Metriken wie Genauigkeit und Präzision verwendet, bei Zusammenfassungsaufgaben ROUGE oder BLEU sowie bei der Generierung von Regex-Code und Aufgaben zur Überprüfung der fehlerfreien Ausführung.
Wie werden Bewertungen eigentlich berechnet?
Sobald Sie festgelegt haben, was Sie messen möchten, besteht der nächste Schritt darin, Ihre Testfälle zu entwerfen. Dies ist eine Reihe von Beispielen (je mehr, desto besser, aber immer unter Abwägung von Wert und Kosten), bei denen Sie Folgendes haben:
- Eingabebeispiel:Eine realistische Einführung Ihres Systems, sobald es in Produktion geht.
- Erwartete Ausgabe (Falls zutreffend): Schlüsselfakt oder Beispiel der gewünschten Ergebnisse.
- Bewertungsmethode: Aufzeichnungsmechanismus zur Ergebnisauswertung.
- Ergebnis oder Erfolg/Misserfolg: Eine berechnete Metrik, die Ihren Testfall auswertet.
Abhängig von Ihren Anforderungen, Ihrer Zeit und Ihrem Budget können Sie verschiedene Techniken als Bewertungsmethoden verwenden:
- Statistische Erfassungstools wie: BLEU, ROUGE und METEOR oder Kosinus-Ähnlichkeitsmaß zwischen Einbettungen – gut zum Vergleichen von generiertem Text mit Referenzausgabe.
- Traditionelle Metriken des maschinellen Lernens wie Genauigkeit, Rückruf und AUC – Am besten für die Klassifizierung mit gekennzeichneten Daten.
- Großes Sprachmodell als Richter (LLM-as-a-Judge) Verwenden Sie ein großes Sprachmodell, um die Ausgabe auszuwerten (z. B. „Ist diese Antwort richtig und hilfreich?„). Besonders nützlich, wenn keine nicht klassifizierten Daten verfügbar sind oder wenn ein offenes Konstrukt ausgewertet wird.
Codebasierte Bewertungen Verwenden Sie reguläre Ausdrücke, Logikregeln oder Testfallimplementierungen, um Formate zu validieren.
Das Endergebnis
Lassen Sie uns alles anhand eines konkreten Beispiels zusammenfassen. Stellen Sie sich vor, Sie erstellen ein System zur Stimmungsanalyse, das Ihrem Kundensupportteam dabei hilft, eingehende E-Mails zu priorisieren.
Das Ziel besteht darin, sicherzustellen, dass auf die dringendsten oder negativsten Nachrichten schneller reagiert wird – wodurch Frustration verringert, die Zufriedenheit verbessert und die Kundenabwanderung verringert wird. Dies ist ein relativ einfacher Anwendungsfall, aber selbst in einem System wie diesem mit begrenzter Ausgabe ist die Qualität entscheidend: Schlechte Vorhersagen können dazu führen, dass E-Mails zufällig priorisiert werden, was bedeutet, dass Ihr Team Zeit mit einem System verschwendet, das Geld kostet.
Woher wissen Sie also, dass Ihre Lösung so gut funktioniert, wie Sie es möchten? Sie bewerten. Hier sind einige Beispiele für Dinge, deren Bewertung in diesem speziellen Anwendungsfall relevant sein könnte:
- Formatvalidierung: Werden die Ausgaben eines Aufrufs eines großen Sprachmodells (LLM) zur Vorhersage der E-Mail-Stimmung im erwarteten JSON-Format zurückgegeben? Dies kann über codebasierte Prüfungen ausgewertet werden: Regex, Schemavalidierung usw.
- Genauigkeit der Stimmungsklassifizierung: Klassifiziert das System die Stimmung in einer Reihe von Texten – kurz, lang und mehrsprachig – richtig? Dies kann anhand von Daten beurteilt werden, die mit herkömmlichen Metriken des maschinellen Lernens (ML-Metriken) gekennzeichnet sind – oder, falls keine Kennzeichnungen verfügbar sind, mithilfe eines großen Sprachmodells (LLM) als Maßstab.
Sobald die Lösung live ist, möchten Sie auch die Kennzahlen einbeziehen, die am engsten mit der endgültigen Wirkung Ihrer Lösung zusammenhängen.:
- Priorisierungseffektivität: Werden Support-Mitarbeiter tatsächlich zu den wichtigsten E-Mails weitergeleitet? Stimmt die Priorisierung mit der gewünschten Geschäftswirkung überein?
- Endgültige Auswirkungen auf das Geschäft: Verkürzt dieses System mit der Zeit die Reaktionszeiten, verringert die Kundenabwanderung und verbessert es die Zufriedenheitswerte?
Bewertungen sind unerlässlich, um sicherzustellen, dass KI-Systeme nützlich, sicher, wertvoll und für Produktionsanwender bereit sind. Egal, ob Sie mit einem einfachen Klassifikator oder einem offenen Chatbot arbeiten, nehmen Sie sich die Zeit, zu definieren, was „gut genug“ (minimale praktikable Qualität) bedeutet – und bauen Sie darauf basierende Bewertungen auf, um dies zu messen!
المراجع
[1]. Ihr KI-Produkt muss evaluiert werdenHamel Husain
[2]. LLM-Bewertungsmetriken: Der ultimative LLM-Bewertungsleitfaden, Confident AI
[3]. Bewertung von KI-Agenten, deeplearning.ai + Arize
Kommentarfunktion ist geschlossen.