

Ich habe die neue native Bildgenerierungsfunktion von Gemini ausprobiert und sie ist absolut fantastisch.
Zusammenfassung:
- Google hat die native Bildgenerierung und -bearbeitung mit der neuen Betaversion von Gemini 2.0 Flash gestartet.
- Die Funktion ist jetzt kostenlos im AI Studio verfügbar und Sie können mit einfachen Textbefehlen eine Reihe koordinierter Bilder erstellen und bearbeiten.
- Sie können Elemente entfernen und hinzufügen, Text einfügen, Bilder einfärben, eine visuelle Geschichte erstellen und vieles mehr.
Den Begriff „nativ multimodal“ hören wir im Bereich der KI schon seit über einem Jahr, doch die Unternehmen haben bisher nur langsam das volle multimodale Potenzial ihrer KI-Modelle ausgeschöpft. Google hat endlich seinen neuesten Prototyp, den „Gemini 2.0 Flash Experimental“, veröffentlicht, mit… Möglichkeit zum Erstellen und Bearbeiten von OriginalbildernHey.
Nun fragen Sie sich vielleicht, welche Bedeutung die Bilderzeugung hat? Die KI-Bildgenerierung ist seit einiger Zeit bei allen wichtigen KI-Chatbots wie ChatGPT verfügbar. Wenn wir KI-Bilder auf ChatGPT oder Gemini generieren, werden diese an ein spezialisiertes diffusionsbasiertes Modell wie Dall-E 3 oder Imagen 3 weitergeleitet. Diese Modelle werden anhand von Bildern trainiert und sind nur für die Generierung von Bildern konzipiert. Es handelt sich um eine Erweiterung des Haupt-KI-Modells und nicht um einen Teil davon.
Allerdings gibt es auch linguistische Vision-Modelle wie Gemini Native Multimediafunktion, d. h., es kann sowohl Text als auch Bilder verstehen, generieren und ändern. Bisher hat kein Technologieunternehmen den Benutzern diese Funktion zur Verfügung gestellt. OpenAI demonstrierte seine native Bildgenerierungsfunktion 4 mit GPT-2024o, aber auch diese wurde nie veröffentlicht.
 Mit der Funktion zur Generierung von Originalbildern erhalten Sie: Bessere Koordination Dabei werden multimodale Modelle anhand eines riesigen Datensatzes unterschiedlicher Medien trainiert. Dadurch verfügen diese Modelle über ein besseres Verständnis der Konzepte und zeigen ein umfassenderes Wissen über die Welt.
Mit der Funktion zur Generierung von Originalbildern erhalten Sie: Bessere Koordination Dabei werden multimodale Modelle anhand eines riesigen Datensatzes unterschiedlicher Medien trainiert. Dadurch verfügen diese Modelle über ein besseres Verständnis der Konzepte und zeigen ein umfassenderes Wissen über die Welt.
Neben der Bildgenerierung können Sie Bilder auch nahtlos mit einfachen Textbefehlen bearbeiten. Laden Sie beispielsweise ein Bild hoch und bitten Sie das Modell, Sonnenbrillen hinzuzufügen, fetten Text einzufügen, Objekte zu entfernen und vieles mehr. Im Gegensatz zu Diffusionsmodellen, die das gesamte Bild mit jedem neuen Befehl neu generieren, bleiben native Multimediamodelle auch nach mehreren Bearbeitungen konsistent.
Erstellen Sie Bilder mit der Gemini 2.0 Flash-Demo
Derzeit ist die ursprüngliche Funktion zur Bilderzeugung für öffentliche Benutzer nicht verfügbar. Die Gemini 2.0 Flash-Demo mit nativer Bildgenerierung ist nur auf der AI Studio-Plattform von Google verfügbar (زيارة) kostenlos.
Nachdem das Modell in AI Studio in der Vorschau angezeigt wurde, wird es in naher Zukunft auf Gemini veröffentlicht, damit es jeder verwenden kann. Ich habe jedoch das neue Gemini-Modell mit der Bilderzeugungsfunktion ausprobiert und es war eine sehr aufregende Erfahrung.
Zunächst habe ich mit einer visuellen Anleitung begonnen, um die Konsistenz der Bildgenerierungsfunktion von Gemini zu demonstrieren. Ich habe Gemini gebeten, eine visuelle Anleitung zur Zubereitung eines Omeletts zu erstellen und für jeden Schritt des Vorgangs ein Foto anzufertigen.
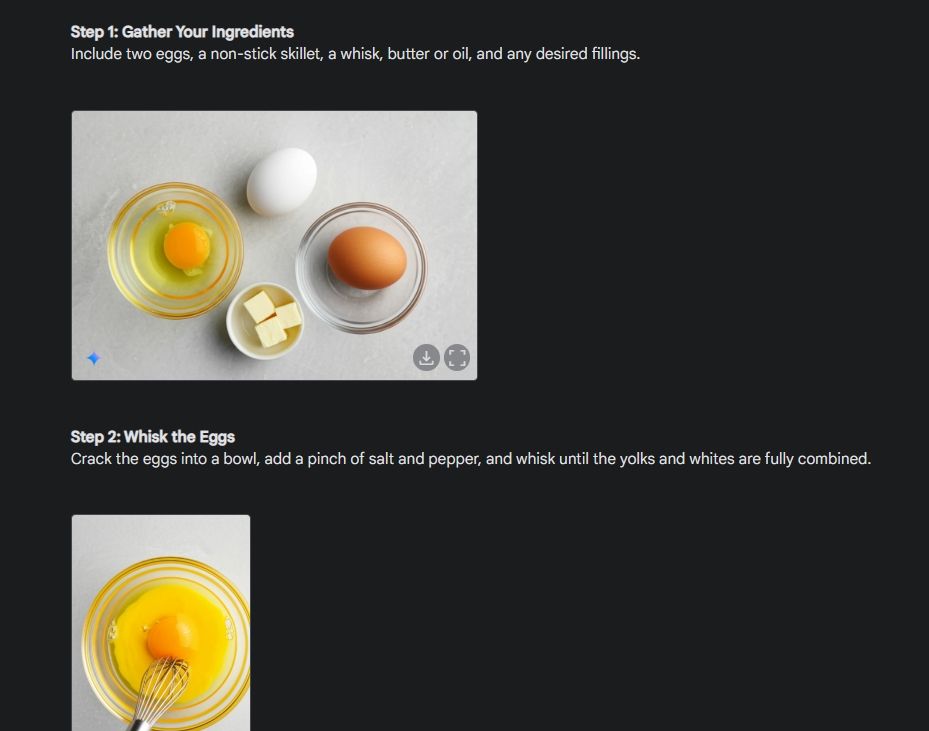
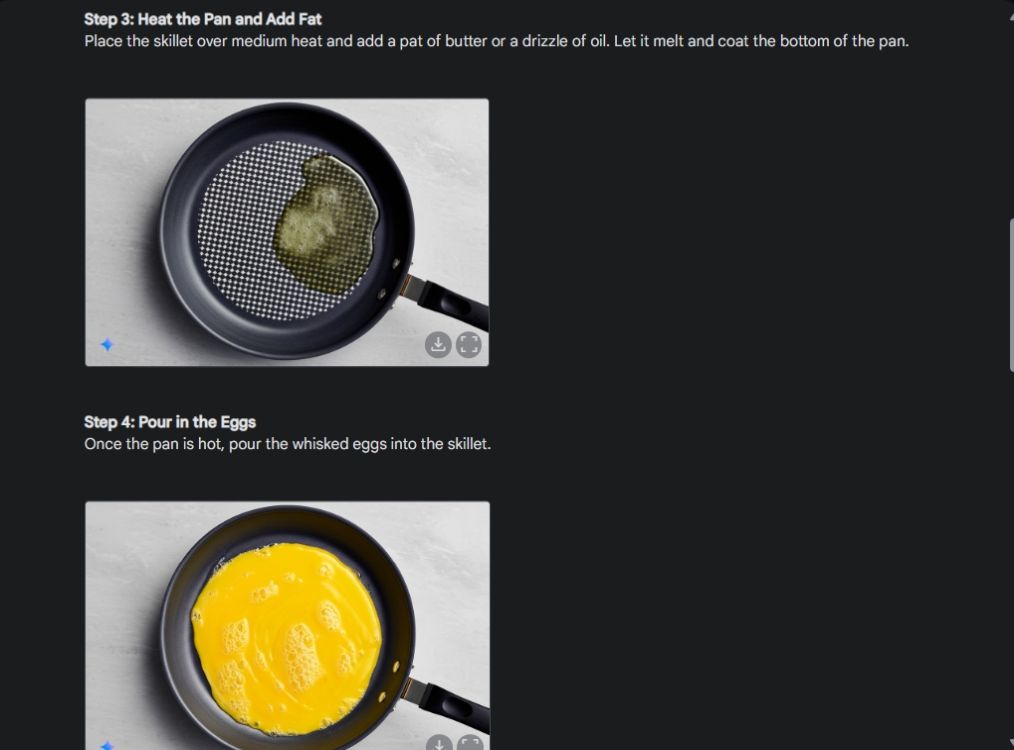

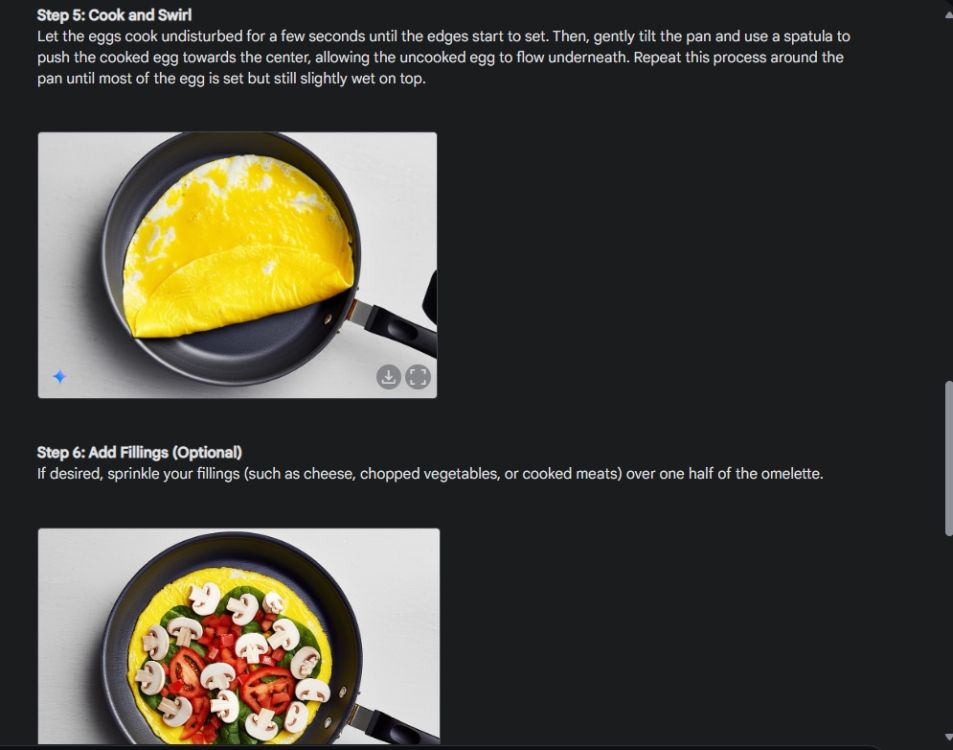
Wie Sie sehen, sind die Ergebnisse über alle Bilder hinweg sehr konsistent und ohne Fehler. Sogar die Schüssel ist die gleiche wie auf dem zweiten Bild. Schließlich können Sie Bilder in einer Auflösung von 1024 x 680 herunterladen. Auf diese Weise können Sie eine visuelle Anleitung zu allem erstellen, was Sie möchten.
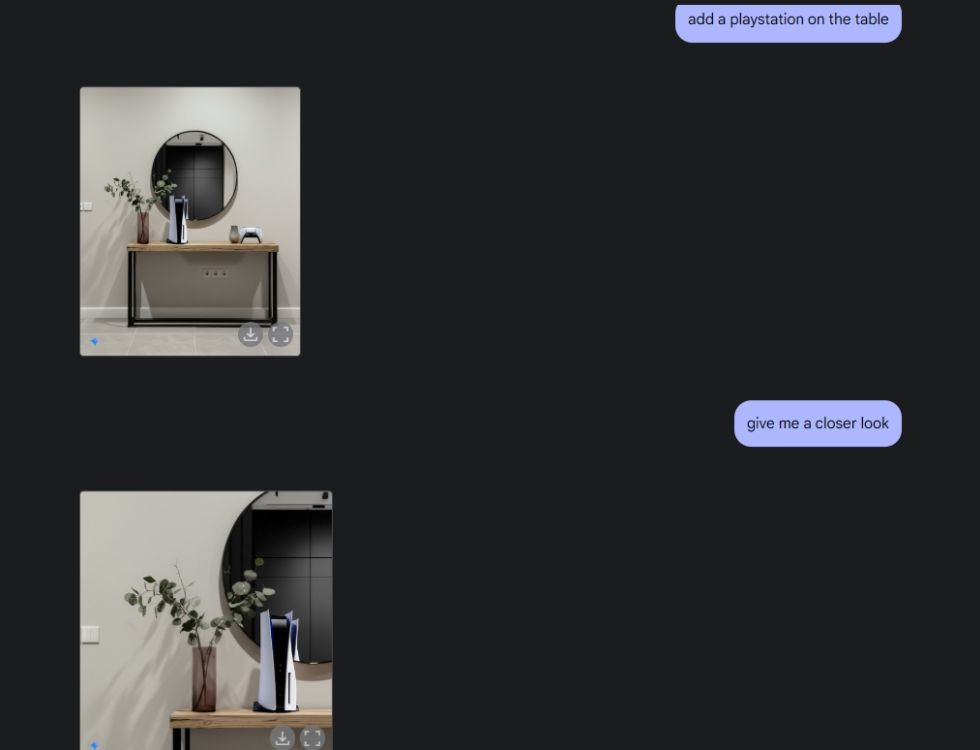
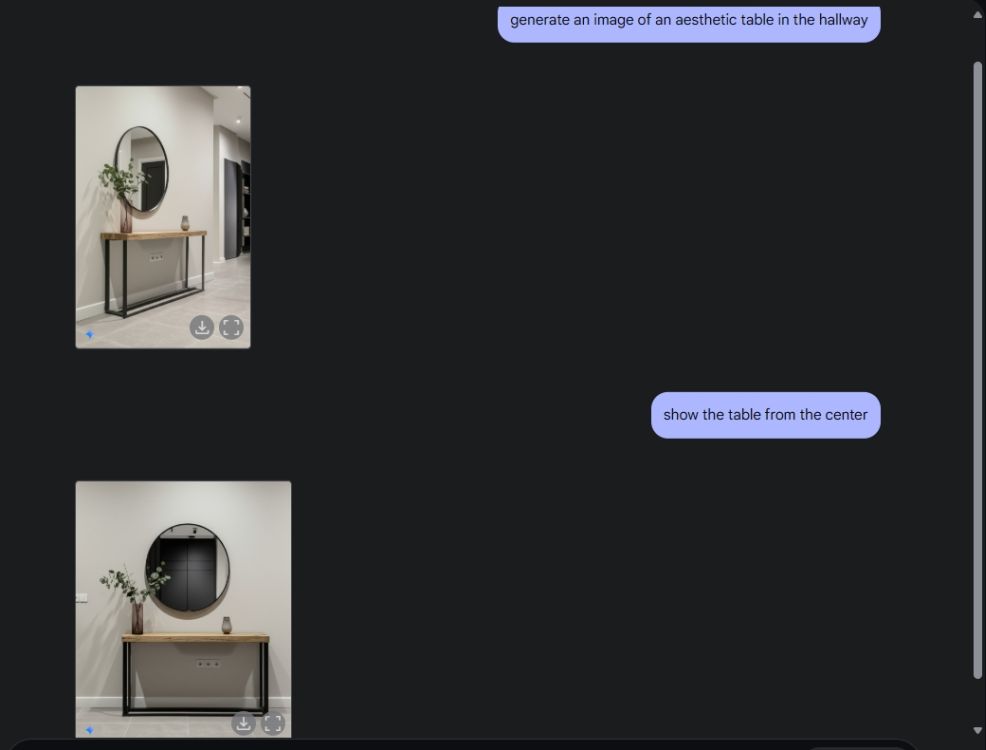
Als Nächstes bat ich Gemini, ein ästhetisches Tischbild zu erstellen und den Tisch dann aus dem mittleren Kamerawinkel zu betrachten. Er hat perfekte Arbeit geleistet. Als nächstes bat ich Gemini, eine PlayStation auf den Tisch zu legen und genauer hinzusehen. Auch dieses Mal hat Gemini den Nagel auf den Kopf getroffen. Wie Sie unten sehen können, enthielt das KI-Modell auch eine Reflexion der PS5 im Spiegel dahinter.
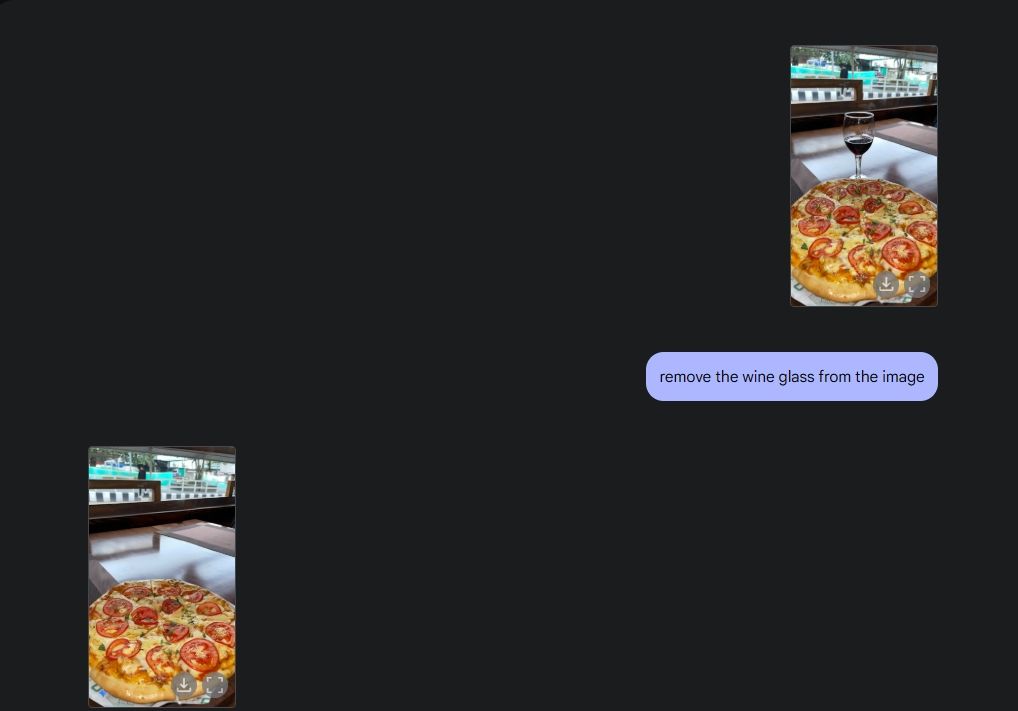
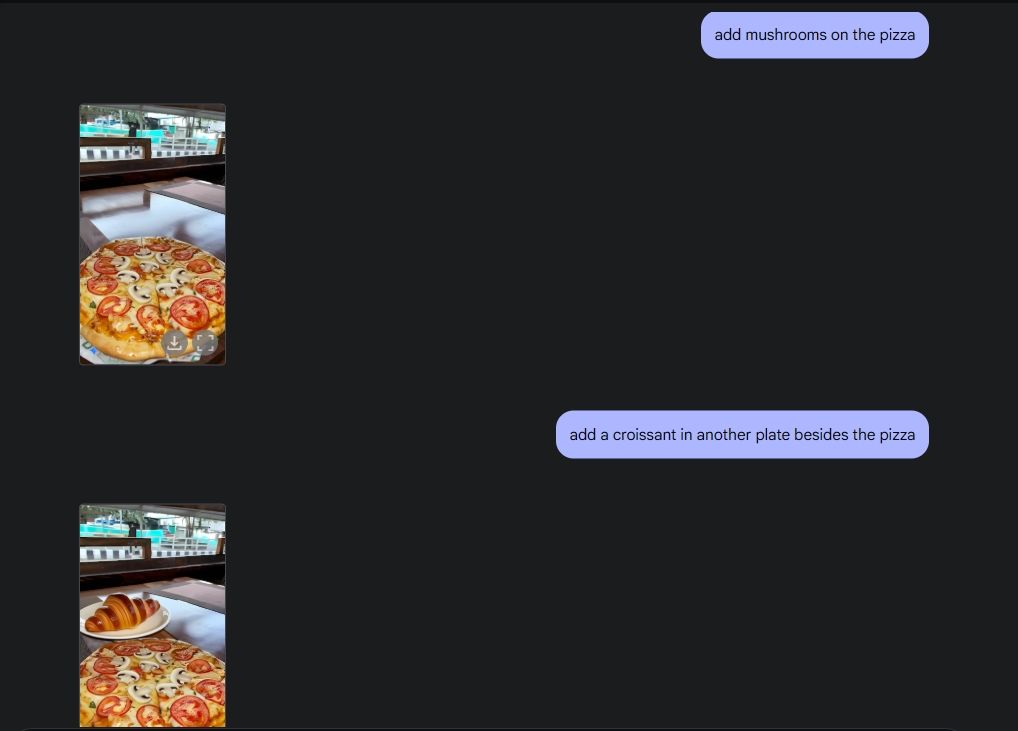
Um die ursprüngliche Fotobearbeitung zu demonstrieren, habe ich ein Foto aus meiner Galerie hochgeladen und Gemini 2.0 gebeten, das Weinglas vom Tisch zu entfernen. Als nächstes bat ich Gemini, der Pizza Pilze hinzuzufügen, und er machte seine Sache großartig. Dann habe ich Gemini gebeten, ein Croissant hinzuzufügen, und da haben Sie es: KI-Fotobearbeitung mit all ihren Funktionen, dank der Multimedia-Fähigkeiten von Gemini.
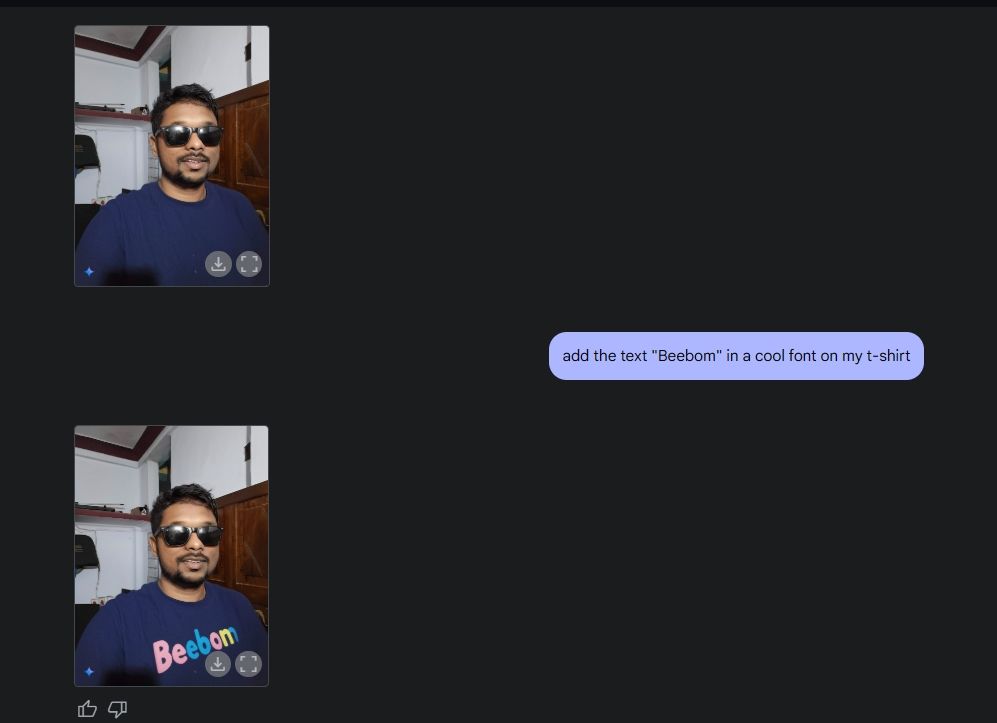
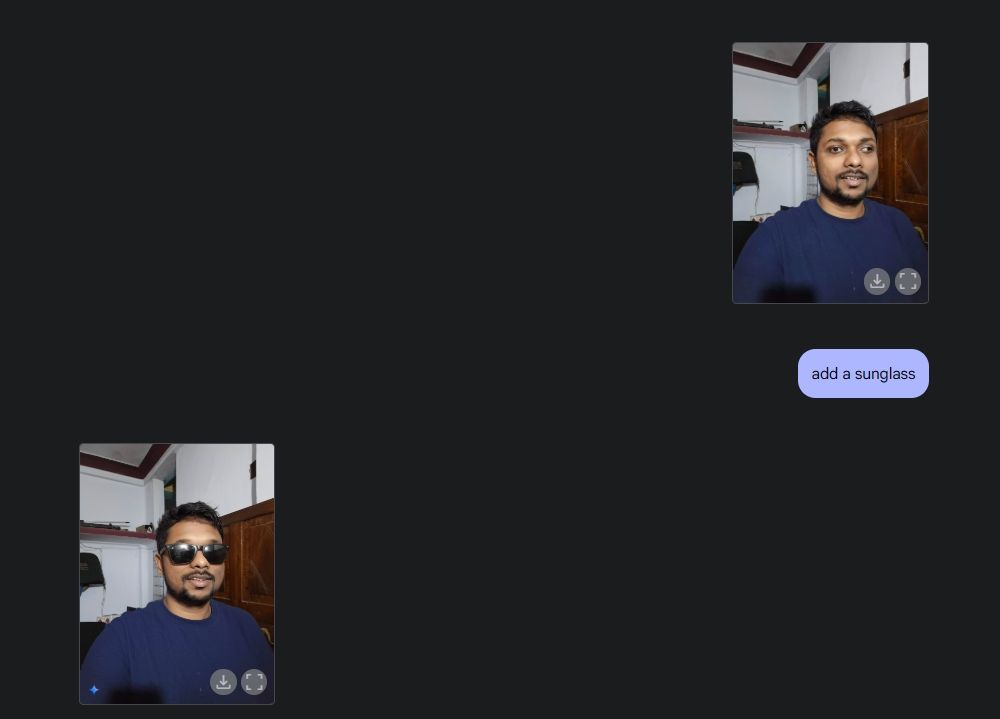
Als Nächstes lud ich ein Foto von mir hoch, bat Gemini, eine Sonnenbrille hinzuzufügen, und fügte dann den Text „Beebom“ zu meinem Shirt hinzu. Beide wurden sehr gut ausgeführt.
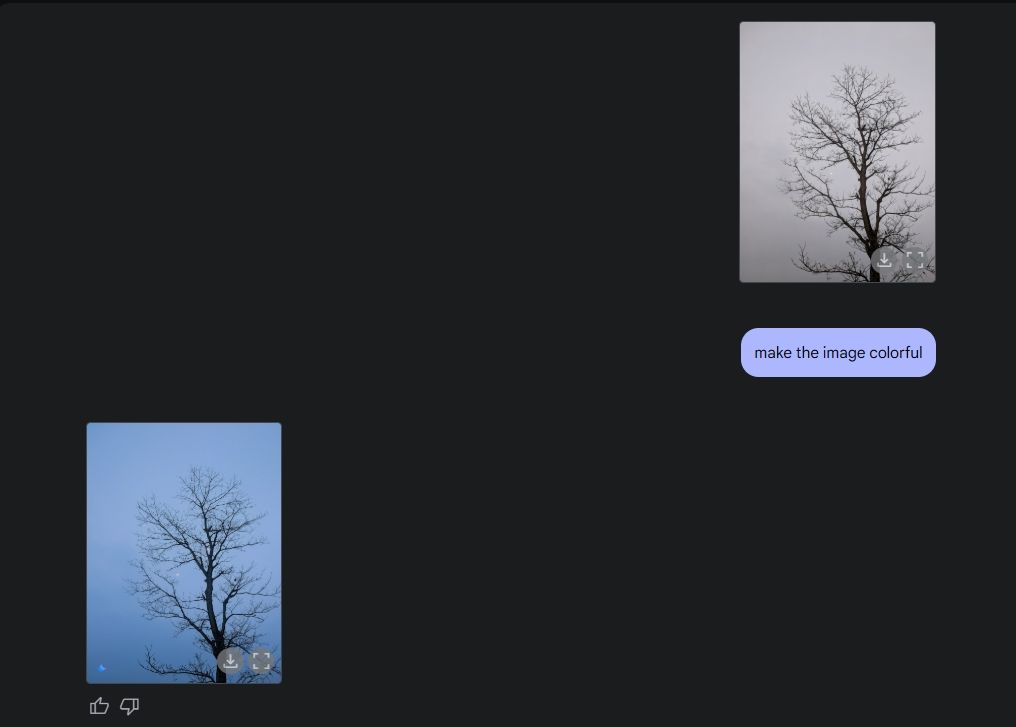
Zum Schluss habe ich Gemini gebeten, ein Bild auszumalen, und auch das hat er gut gemacht. Ich meine, das Bild ist schöner als vorher, ohne seltsame Fehler, Verzerrungen oder fehlende Bildteile.
Es gibt viele Anwendungsfälle, die Sie mit den neuen Multimediafunktionen von Gemini erleben können. Google hat bei der nativen Bilderstellung und -bearbeitung großartige Arbeit geleistet und ich habe vor, die Funktion in den kommenden Wochen ausführlicher zu nutzen, um ihre Grenzen auszutesten.
Nach der Veröffentlichung von Veo 2 zur Videoerstellung und Imagen 3 zur speziellen Bildbearbeitung scheint Google OpenAI in vielen Bereichen übertroffen zu haben. Nicht nur im Bereich der KI-Textgenerierung. Es wird also interessant sein zu sehen, was OpenAI unternimmt, um mit ChatGPT die Führung zurückzugewinnen.
Kommentarfunktion ist geschlossen.