

Publikumswertung: 27 KI-Modelle, ChatGPT auf Platz 8 – Hier sind die Modelle, die es übertroffen haben
Obwohl die Welt Künstliche Intelligenz (KI) Obwohl es oft wie ein turbulenter Bereich erscheint, finden hinter den Kulissen überraschend viele Analysen, Benchmarkings und Tests statt – nicht nur von den Unternehmen selbst, sondern auch von Gruppen, die gegründet wurden, um ihre eigenen Rankings zu bestimmen.

Diese Gruppen testen alles von der Fähigkeit eines Chatbots, Mathetests zu absolvieren,
Erstellen Sie Bilder, oder logische Erklärungen liefern, oder sogar medizinische Ratschläge geben, oder einfach zeigen, wie emotional intelligent sie ist.
Bei diesen verschiedenen Tests zeigen die Modelle ihre Stärken und Schwächen in verschiedenen Bereichen. Während beispielsweise GPT-5 Er ist ein hervorragender wissenschaftlicher Schlussfolgerungskünstler, bleibt jedoch in seiner Fähigkeit, sich an neue Konzepte anzupassen, hinter Leuten wie Gemini und Claude zurück.
Jeder dieser Tests verrät uns etwas Neues über KI-Modelle und ist wichtig, um uns daran zu erinnern, welche Tools in verschiedenen Szenarien am besten geeignet sind. Oft fehlt jedoch eine Kennzahl: Welche KI-Modelle bieten die beste Benutzererfahrung?
Humaine-Klassifizierungssystem
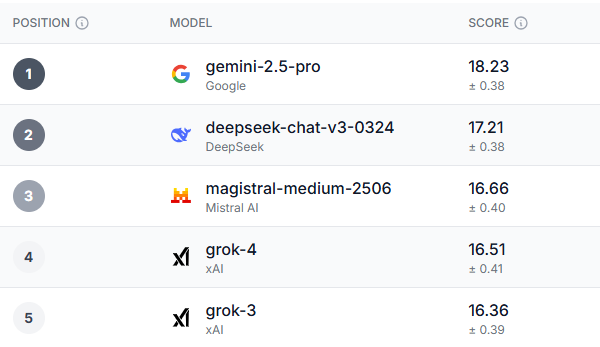
Ein in Großbritannien ansässiges Technologieunternehmen namens Prolific hat Eine KI-Bestenliste namens HumaineAnstatt die Fähigkeit der KI zu testen, Aufgaben zu erledigen, testete Prolific mit diesen Modellen unterschiedliche Benutzererfahrungen.
Durch die Auswertung der Erfahrungen von 21,352 Personen mit den Tools konnten sie nicht nur einen Gesamtsieger ermitteln, sondern die Ergebnisse auch nach Alter, Standort (die Tests wurden sowohl in Großbritannien als auch in den USA durchgeführt) und politischer Überzeugung aufschlüsseln.
Hierzu zählen Einzeleinträge für:
- Vereinigtes Königreich: Altersgruppen
- Vereinigtes Königreich: Rennen
- Vereinigtes Königreich: Politischer Standpunkt
- Vereinigte Staaten: Altersgruppen
- Vereinigte Staaten: Rasse
- Vereinigte Staaten: Politischer Standpunkt
Das Team ließ jeden Teilnehmer in einem Vergleich mit zwei separaten KI-Modellen interagieren und bat sie, Feedback dazu zu geben, welches Modell bei jeder Interaktion besser abschnitt.
Daraus ergaben sich ein Gesamtsieger und eine Bestenliste für die Leistung, aber auch separate Ranglisten für die Leistung bei grundlegenden Aufgaben und das logische Denken sowie ein Gewinner für Kommunikation, Belastbarkeit, Vertrauen und Ethik.
Was zeigen die Ergebnisse?

Nach einer gründlichen Überprüfung zeichnete sich ein klarer Sieger ab, nicht nur in der Kategorie Gesamtleistung, sondern auch in den meisten Unterkategorien. Der Gemini 2.5-Pro übertraf in nahezu jedem im Test untersuchten Benchmark die Erwartungen.
Junge Menschen im Alter von 18 bis 34 Jahren in Großbritannien, demokratische Wähler und die über 55-Jährigen in den USA stimmten darin überein, dass Gemini 2.5 Pro Es ist insgesamt das beste Modell. Nur in den Bereichen Vertrauen, Ethik und Sicherheit schnitten alle demografischen Gruppen besser ab als Gemini, und zwar in Grok-3 – ein ironisches Ergebnis angesichts der Sicherheits- und Ethikprobleme, mit denen KI-Modelle in letzter Zeit konfrontiert waren.
Interessanterweise sind die drei Modelle, die nach Gemini entstanden sind, Deepseek, Magistral Le Chat und GrokDeepseek erfreute sich Anfang des Jahres großer Beliebtheit, ist aber in letzter Zeit von der Bildfläche verschwunden. Le Chat hingegen ist ein weniger beliebter Chatbot, hat aber eine treue Fangemeinde.
Wo passt also das weltberühmte ChatGPT in all das hinein? Es steht am Ende der Liste, auf dem achten Platz mit dem am höchsten bewerteten GPT-4.1-Modell. Noch schlimmer ist Claude, wo die vier Ausgaben in der Gesamtwertung den elften und zwölften Platz belegten.
Was bedeutet das alles?
Heißt das, dass Gemini der beste KI-Chatbot der Welt ist? Heißt das, Sie sollten ChatGPT aufgeben…? Nun, nicht ganz.
Diese Ergebnisse spiegeln nicht unbedingt die Leistung dieser Modelle wider. Bei Tests mit den meisten anderen Metriken stehen ChatGPT, Gemini, Claude und Grok normalerweise ganz oben.
Dies ist jedoch eine wichtige Ergänzung zu diesen Tests. Sie helfen uns, KI aus der Perspektive menschlicher Erfahrung besser zu verstehen. Beispielsweise schneidet Le Chat bei Standard-Benchmarks nicht besonders gut ab, wird aber oft als hervorragende Wahl in Bezug auf Erfahrung und Vertrauenswürdigkeit genannt.
Während die Leistungen von Anthropic und OpenAI in dieser Testrunde dieses Niveau nicht ganz erreichten, zeigten sowohl Gemini als auch Grok erneut eine starke Leistung. Beide Unternehmen erzielen bei Standard-Benchmarks häufig hohe Werte und taten dies auch hier.
Kommentarfunktion ist geschlossen.