

Nvidia hilft bei der Lösung der größten Herausforderungen der KI-Bildgenerierung.
Ein hoher Leistungs- und Rechenbedarf ist ein grundlegendes Problem der KI, insbesondere bei Aufgaben wie der Medienerstellung. Wenn diese Aufgaben auf Mobiltelefonen lokal ausgeführt werden, können nur wenige teure Geräte mit leistungsstarken Prozessoren den Funktionsumfang ausführen. Selbst wenn es in großem Maßstab in der Cloud implementiert wird, ist es ein teurer Prozess.
Nvidia hat sich dieser Herausforderung möglicherweise in Zusammenarbeit mit dem MIT und der Tsinghua-Universität stillschweigend gestellt. Das Team hat ein hybrides KI-Bilderzeugungstool namens HART (Hybrid Auto Transformer) kombiniert im Wesentlichen zwei der am häufigsten verwendeten KI-Bilderzeugungstechniken. Das Ergebnis ist ein sehr schnelles Tool mit deutlich geringeren Rechenanforderungen.
Um Ihnen eine Vorstellung davon zu geben, wie schnell sie ist, habe ich sie gebeten, ein Bild von einem Papagei zu erstellen, der Bassgitarre spielt. Das nächste Bild wurde in nur etwa einer Sekunde zurückgegeben. Ich konnte mit dem Fortschrittsbalken kaum Schritt halten. Wenn ich die gleiche Eingabe mit einem Formular verwende Google-Bild 3 Bei Gemini dauerte es bei einer 9-Mbit/s-Internetverbindung etwa 10–200 Sekunden.

Ein gewaltiger Sprung in der Bilderzeugung durch künstliche Intelligenz
Als KI-Bilder an Bedeutung gewannen, war die Diffusionstechnologie die treibende Kraft hinter allem und trieb Produkte wie den Dall-E-Bildgenerator von OpenAI, Imagen von Google und Stable Diffusion an. Mit dieser Methode entstehen hochauflösende und detailreiche Bilder. Allerdings sind zum Generieren von KI-Bildern mehrere Schritte erforderlich, was den Vorgang langsam und rechenintensiv macht.
Der zweite Ansatz, der in letzter Zeit an Popularität gewonnen hat, sind selbstregressive Modelle, die ähnlich wie Chatbots funktionieren und Bilder mithilfe der Pixelvorhersagetechnologie generieren. Diese Methode ist schneller, aber auch fehleranfälliger bei der KI-Bildgenerierung.
Ein Team am MIT hat beide Methoden in einem einzigen Paket namens HART kombiniert. Diese Technik basiert auf einem autoregressiven Modell, um komprimierte Bildelemente als diskrete Token vorherzusagen, während ein kleines Diffusionsmodell sich um den Rest kümmert, um den Qualitätsverlust auszugleichen. Durch diesen Ansatz wird die Anzahl der erforderlichen Schritte von über zwanzig auf nur acht reduziert.
Die Experten hinter HART behaupten, dass diese Technologie „Bilder erzeugt, die der Qualität modernster Diffusionsmodelle entsprechen oder diese übertreffen, und das alles ungefähr neunmal schneller.“ HART kombiniert ein autoregressives Modell mit einem Bereich von 700 Millionen Parametern und ein kleines Diffusionsmodell, das 37 Millionen Parameter verarbeiten kann.

Lösung der Computerkostenkrise
Interessanterweise konnte dieses hybride HART-Tool Bilder erzeugen, die so gut waren wie hochmoderne Modelle mit einer Kapazität von 2 Milliarden Parametern. Das Wichtigste dabei ist, dass HART dieses Kunststück durch eine neunmal schnellere Bilderzeugung erreichen konnte, während gleichzeitig die Rechenressourcen um 31 % reduziert wurden.
Laut dem Team ermöglicht der Ansatz mit geringem Rechenaufwand, dass HART nativ auf Telefonen und Laptops läuft, was ein großer Erfolg ist. Bisher erfordern beliebte Marktprodukte wie ChatGPT und Gemini eine Internetverbindung zum Generieren von Bildern, da die Berechnung auf Cloud-Servern erfolgt.
Im Testvideo demonstrierte das Team, dass es nativ auf einem MSI-Laptop mit einem Prozessor der Intel Core-Serie und einer Nvidia GeForce RTX-Grafikkarte läuft. Diese Kombination finden Sie in den meisten Gaming-Laptops auf dem Markt, ohne ein Vermögen ausgeben zu müssen.

HART kann Bilder im Seitenverhältnis 1:1 mit einer Auflösung von 1024 x 1024 Pixeln erzeugen. Der Detailgrad dieser Bilder ist beeindruckend, ebenso wie die stilistische Vielfalt und Genauigkeit der Szene. Während des Tests stellte das Team fest, dass das hybride KI-Tool drei- bis sechsmal schneller war und eine mehr als siebenmal höhere Produktivität lieferte.
Die zukünftigen Möglichkeiten sind spannend, insbesondere wenn die Bildfunktionen von HART mit Sprachmodellen kombiniert werden. „In Zukunft könnte man mit einem einheitlichen generativen Modell aus Sehen und Sprache interagieren, etwa indem man es auffordert, die Zwischenschritte anzuzeigen, die zum Zusammenbau eines Möbelstücks erforderlich sind“, sagt das MIT-Team.
Sie untersuchen diese Idee bereits und planen sogar, HARTs Ansatz zur Audio- und Videogenerierung zu testen. Sie können es anprobieren Web-Kontrollfeld MIT.
Einige Nachteile
Bevor wir uns in die Qualitätsdiskussion vertiefen, sei darauf hingewiesen, dass es sich bei HART noch um ein Forschungsprojekt in der Anfangsphase handelt. Das Team hat auf einige technische Hindernisse hingewiesen, beispielsweise auf einen erhöhten Overhead während der Inferenz- und Trainingsverfahren. Es wird erwartet, dass dieses Programm in naher Zukunft bedeutende Entwicklungen erleben wird.
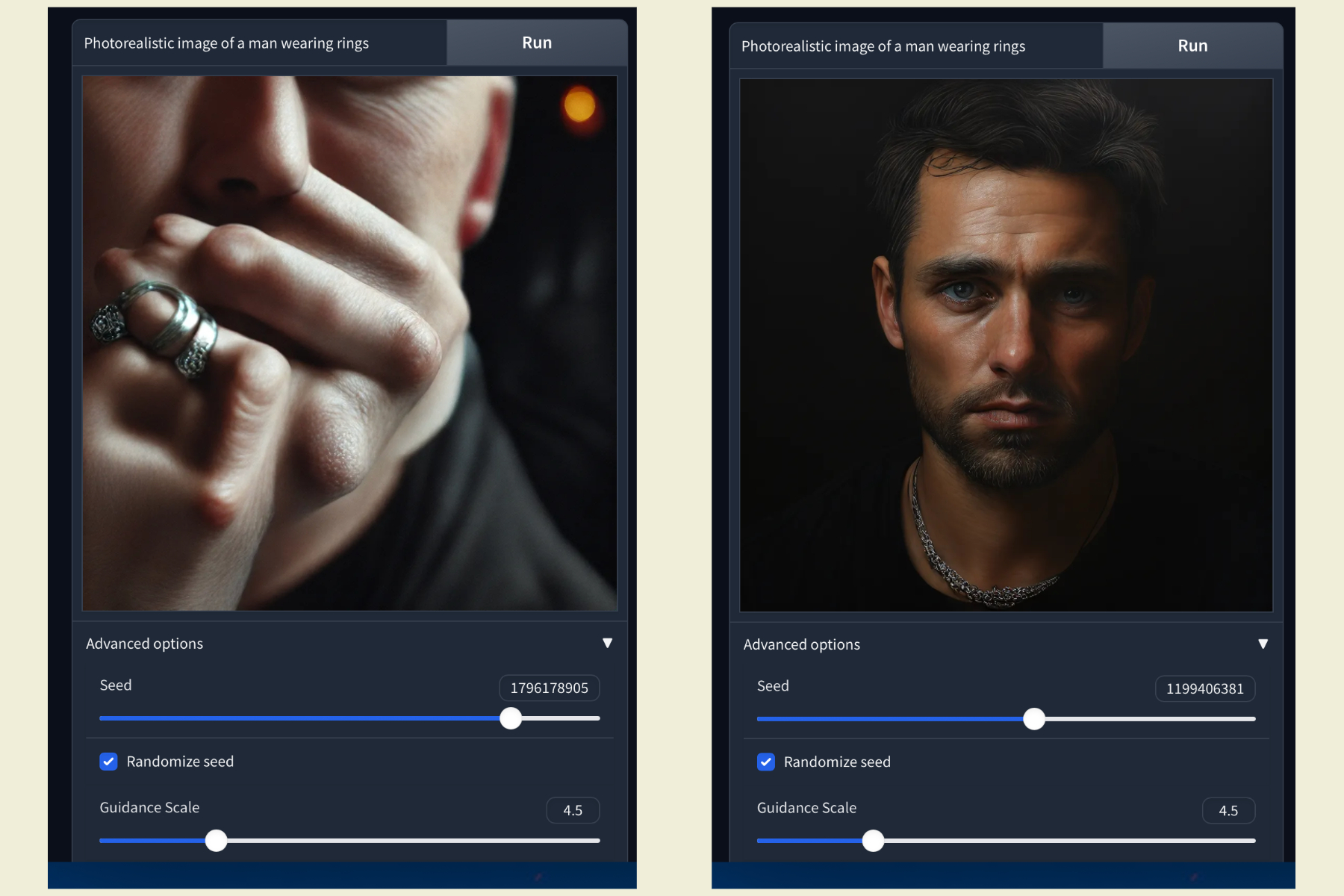
Diese Herausforderungen können behoben oder übersehen werden, da sie im Gesamtzusammenhang unbedeutend sind. Angesichts der enormen Vorteile, die HART hinsichtlich Rechenleistung, Geschwindigkeit und Latenz bietet, können diese Herausforderungen zudem bestehen bleiben, ohne dass es zu nennenswerten Leistungsproblemen kommt.
Während meiner kurzen Erfahrung mit HART unter Verwendung von Textaufforderungen war ich erstaunt, wie schnell die Bilder generiert wurden. Mir ist noch nie ein Szenario begegnet, in dem die Freeware länger als zwei Sekunden zum Erstellen eines Bildes brauchte. Selbst bei Eingabeaufforderungen, die sich über drei Absätze (fast 200 Wörter) erstreckten, konnte HART Bilder generieren, die perfekt zur Beschreibung passten.
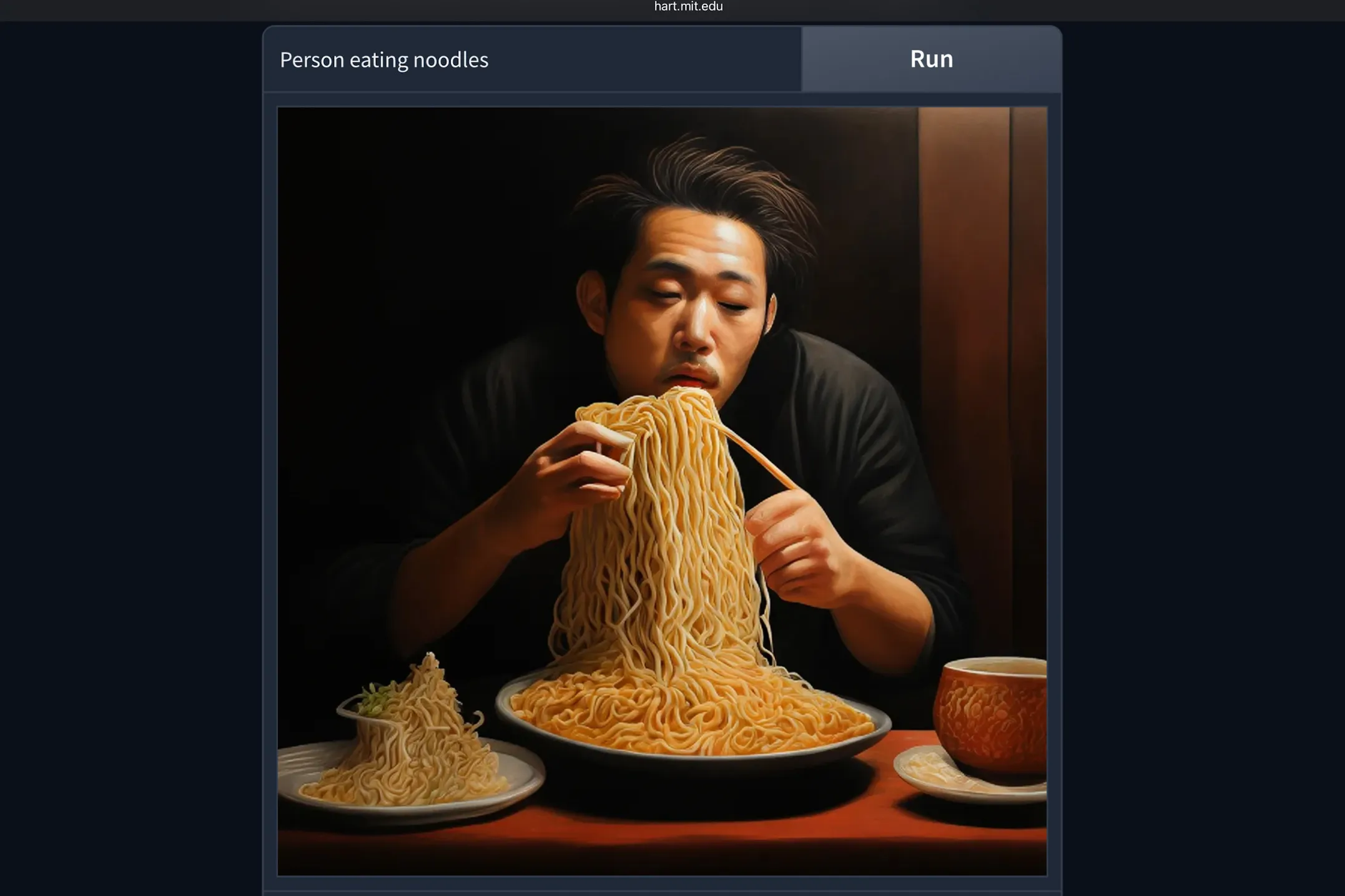
Abgesehen von der Genauigkeit der Beschreibung waren die Bilder sehr detailliert. Allerdings weist HART die gleichen Nachteile auf wie typische KI-Bilderzeugungssoftware. Er hat Schwierigkeiten, grundlegende Figuren und Zeichnungen zu erstellen, etwa beim Essen, bei der Charakterausrichtung und beim Erfassen der Perspektive.
Der Realismus im menschlichen Kontext ist ein Bereich, in dem mir deutliche Mängel aufgefallen sind. In einigen Fällen missverstand das Programm grundlegende Dinge, beispielsweise verwechselte es einen Ring mit einer Halskette. Aber insgesamt handelte es sich nur um wenige Fehler, und diese waren zu erwarten. Viele KI-Tools können dies noch immer nicht richtig, obwohl es sie schon seit einiger Zeit gibt.
Insgesamt bin ich vom enormen Potenzial von HART sehr begeistert. Es wird interessant zu sehen sein, ob MIT und Nvidia daraus ein Produkt entwickeln oder den hybriden KI-Bildgenerierungsansatz einfach in ein bestehendes Produkt übernehmen. So oder so ist es ein Blick in eine vielversprechende Zukunft.
Kommentarfunktion ist geschlossen.