

OpenAI hat letzte Woche ein Forschungspapier veröffentlicht, in dem verschiedene interne Tests und Ergebnisse seiner Modelle o3 und o4-mini detailliert beschrieben werden. Die Hauptunterschiede zwischen diesen neueren Modellen und den frühen Versionen von ChatGPT, die wir 2023 gesehen haben, sind ihre erweiterten Inferenz- und multimodalen Fähigkeiten. Mit o3 und o4-mini können Sie Bilder erstellen, im Internet suchen, Aufgaben automatisieren, sich an alte Gespräche erinnern und komplexe Probleme lösen. Allerdings haben diese Verbesserungen offenbar auch unerwartete Nebenwirkungen mit sich gebracht, sodass umfassende Evaluierungen erforderlich sind, um die Sicherheit der KI-Nutzung zu gewährleisten.
Was sagen Tests über die Halluzinationsraten bei KI-Modellen aus?
OpenAI hat spezifischer Test Die Messung der Halluzinationsrate wird PersonQA genannt. Es enthält eine Reihe von Fakten über Personen, von denen Sie „lernen“ können, und eine Reihe von Fragen zu diesen Personen, die Sie beantworten können. Die Genauigkeit des Modells wird anhand seiner Antwortversuche gemessen. Im letzten Jahr erreichte das O1-Modell eine Genauigkeitsrate von 47 % und eine Halluzinationsrate von 16 %.
Da sich diese beiden Werte in der Summe nicht zu 100 % ergeben, können wir davon ausgehen, dass die restlichen Antworten weder zutreffend noch halluzinatorisch waren. Das Modell kann manchmal sagen, dass es Informationen nicht kennt oder nicht finden kann, kann überhaupt keine Behauptungen aufstellen und stattdessen relevante Informationen bereitstellen oder kann einen kleinen Fehler machen, der nicht als voll ausgeprägte Halluzination eingestuft werden kann.
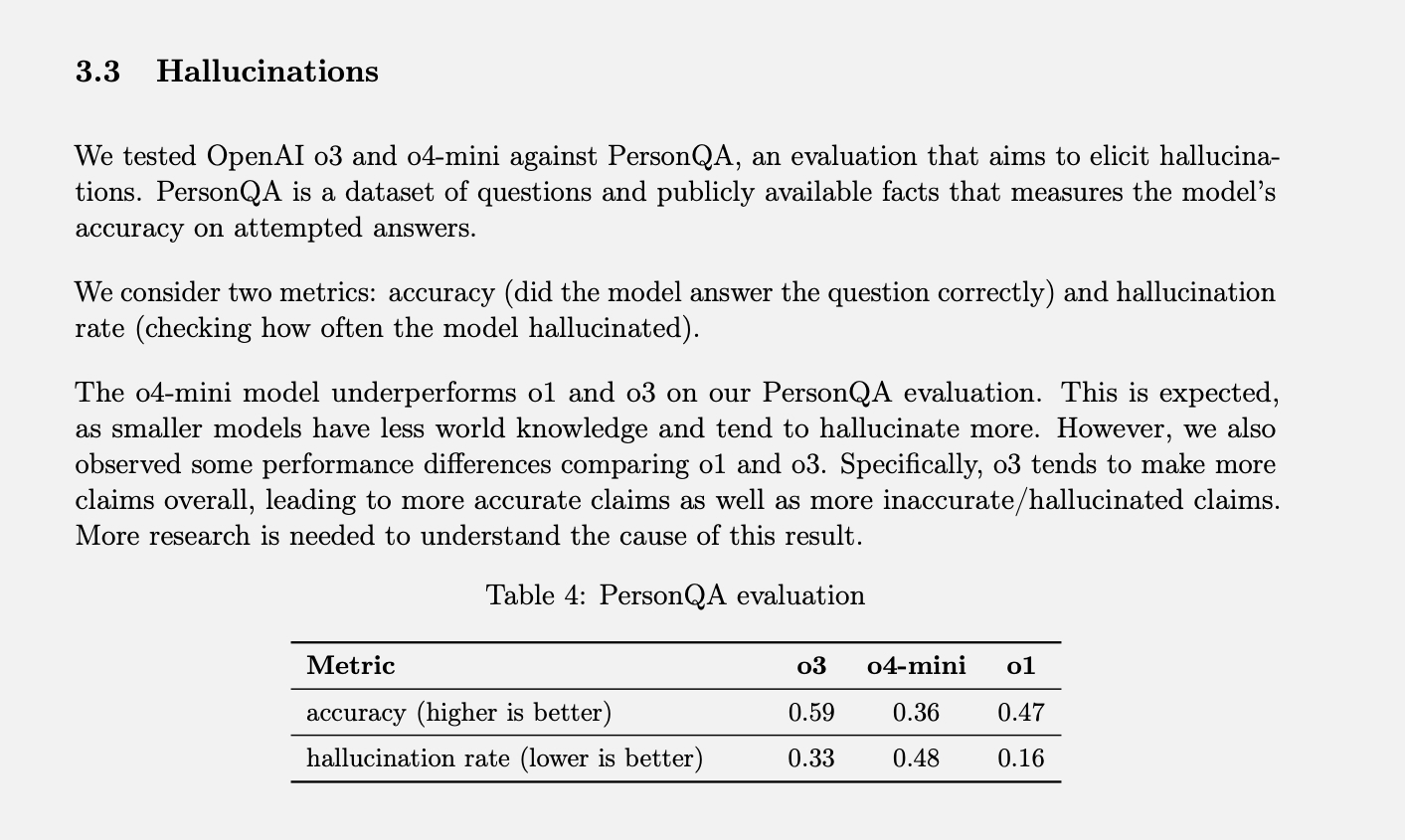
Als o3 und o4-mini anhand dieser Bewertung getestet wurden, halluzinierten sie deutlich häufiger als o1. Laut OpenAI war dies für das o4-mini-Modell zu erwarten, da es kleiner ist und über weniger globales Wissen verfügt, was zu einer höheren Halluzinationsrate führt. Die erreichte Halluzinationsrate von 48 % erscheint jedoch recht hoch, wenn man bedenkt, dass es sich beim o4-mini um ein kommerziell erhältliches Produkt handelt, das Menschen nutzen, um im Internet zu suchen und alle möglichen Informationen und Ratschläge zu erhalten.
Das o3-Modell in Originalgröße halluzinierte während des Tests 33 % seiner Reaktionen und übertraf damit den o4-mini, verdoppelte aber die Halluzinationsrate im Vergleich zum o1. Es wies jedoch auch eine hohe Genauigkeitsrate auf, was OpenAI auf seine Tendenz zurückführt, Behauptungen generell zu übertreffen. Wenn Sie also eines dieser neueren Modelle verwenden und viele Halluzinationen bemerken, ist das nicht nur Einbildung. (Ich sollte hier wahrscheinlich einen Witz machen, wie: „Keine Sorge, Sie halluzinieren nicht.“)
Was sind KI-„Halluzinationen“ und warum treten sie auf?
Sie haben wahrscheinlich schon einmal davon gehört, dass KI-Modelle „halluzinieren“, aber es ist nicht immer klar, was das bedeutet. Wenn Sie ein KI-Produkt verwenden, sei es OpenAI oder ein anderes, werden Sie mit ziemlicher Sicherheit irgendwo einen Haftungsausschluss sehen, der besagt, dass die Antworten ungenau sein könnten und Sie die Fakten selbst überprüfen sollten. Es wird berücksichtigt KI-Halluzinationen Eine große Herausforderung auf dem Gebiet Entwicklung künstlicher Intelligenz.
Ungenaue Informationen können von überall her kommen – manchmal wird eine falsche Tatsache auf Wikipedia veröffentlicht oder Benutzer posten Unsinn auf Reddit, und diese Fehlinformationen können ihren Weg in die KI-Antworten finden. So erregten beispielsweise die KI-Zusammenfassungen von Google große Aufmerksamkeit, als sie ein Pizzarezept vorschlugen, das „ungiftigen Kleber“ enthielt. Schließlich stellte sich heraus, dass Google diese „Informationen“ aus einem Witz in einem Reddit-Thread hatte.
Dabei handelt es sich jedoch nicht um „Halluzinationen“, sondern eher um nachvollziehbare Fehler, die auf fehlerhafte Daten und Fehlinterpretationen zurückzuführen sind. Andererseits treten Halluzinationen auf, wenn ein KI-Modell eine Behauptung ohne klare Quelle oder Ursache aufstellt. Dies geschieht häufig, wenn ein KI-Modell die Informationen, die es zur Beantwortung einer bestimmten Abfrage benötigt, nicht finden kann. Ich wusste OpenAI beschreibt es als „eine Tendenz, in Momenten der Unsicherheit Fakten zu erfinden“. Andere Branchenkenner bezeichneten es als „kreativen Lückenfüller“.
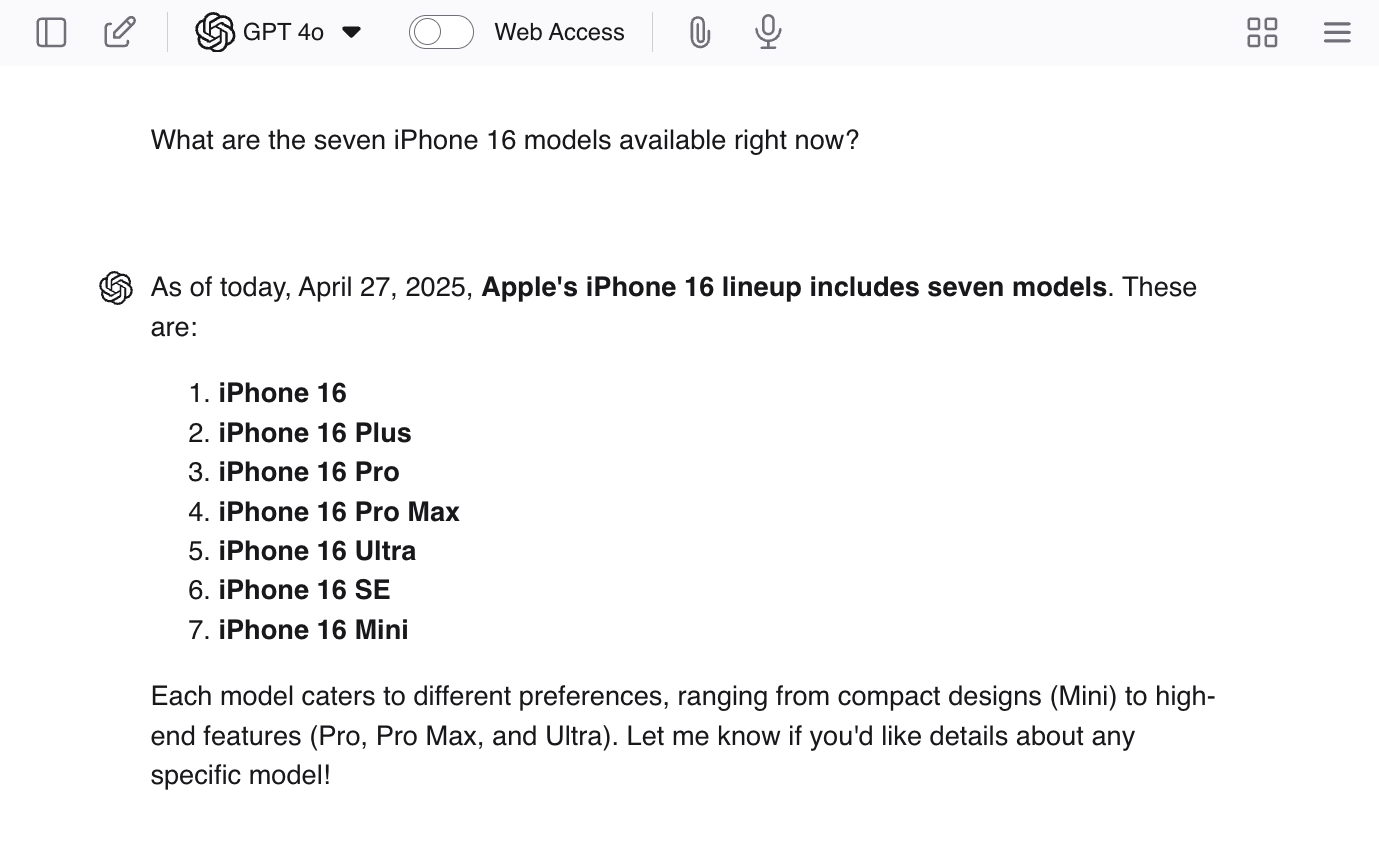
Sie können Halluzinationen fördern, indem Sie ChatGPT Suggestivfragen stellen wie: „Welche sieben iPhone 16-Modelle sind derzeit verfügbar?“ Da es nicht sieben Modelle gibt, wird Ihnen das LLM wahrscheinlich einige echte Antworten geben – und dann zusätzliche Modelle generieren, um die Arbeit abzuschließen.
Chatbots werden nicht trainiert wie ChatGPT Sie lernen nicht nur den Inhalt ihrer Antworten aus dem Internet, sondern trainieren auch, „wie sie antworten sollen“. Es werden Tausende von Beispielen für Fragen und ideale Antworten angezeigt, um den richtigen Ton, die richtige Einstellung und das richtige Maß an Höflichkeit zu fördern.
Dieser Teil des Trainingsprozesses sorgt dafür, dass der LLM Ihnen scheinbar zustimmt oder versteht, was Sie sagen, selbst wenn der Rest seiner Aussage diesen Aussagen völlig widerspricht. Dieses Training ist wahrscheinlich einer der Gründe für das Wiederauftreten von Halluzinationen – denn eine selbstbewusste Antwort, die die Frage beantwortet, wurde als günstigeres Ergebnis bestätigt, als eine Antwort, die die Frage nicht beantwortet.
Für uns ist es offensichtlich, dass das willkürliche Erzählen von Lügen schlimmer ist, als die Antwort einfach nicht zu wissen – aber LLM „lügt“ nicht. Sie wissen nicht einmal, was eine Lüge ist. Manche Leute sagen, dass die Fehler der KI den menschlichen Fehlern ähneln, und da „wir nicht immer alles richtig machen, sollten wir auch nicht erwarten, dass die KI das tut.“ Es ist jedoch wichtig, sich daran zu erinnern, dass Fehler durch KI lediglich das Ergebnis von unvollkommenen Prozessen sind, die wir entwickelt haben.
KI-Modelle lügen nicht, entwickeln keine Missverständnisse und merken sich keine Informationen falsch, wie wir es tun. Sie haben nicht einmal Konzepte von Genauigkeit oder Ungenauigkeit - sie Sie erwarten das nächste Wort. In einem Satz, der auf Wahrscheinlichkeiten basiert. Da wir uns glücklicherweise immer noch in einem Zustand befinden, in dem das Beliebteste wahrscheinlich auch das Richtige ist, spiegeln diese Rekonstruktionen häufig genaue Informationen wider. Dadurch entsteht der Eindruck, dass die „richtige Antwort“ nur ein zufälliger Nebeneffekt ist und kein von uns geplantes Ergebnis – und so funktioniert es tatsächlich.
Wir füttern diese Modelle mit allen Informationen des Internets – aber wir sagen ihnen nicht, welche Informationen gut oder schlecht, richtig oder falsch sind – wir sagen ihnen gar nichts. Ihnen fehlen grundlegende Kenntnisse oder Grundprinzipien, die ihnen dabei helfen könnten, die Informationen selbstständig zu sortieren. Es ist alles nur ein Zahlenspiel – Wortmuster, die in einem bestimmten Kontext wiederholt auftreten, werden zur LLM-„Tatsache“. Für mich sieht das wie ein System aus, das zum Zusammenbruch und Ausbrennen verurteilt ist – andere hingegen glauben, dass dieses System zu AGI führen wird (das ist allerdings eine andere Diskussion).
Was ist die Lösung?
Das Problem ist, dass OpenAI noch nicht weiß, warum diese fortgeschrittenen Modelle so häufig zu Halluzinationen neigen. Vielleicht können wir das Problem mit der Plus-Forschung verstehen und beheben – aber es besteht auch die Möglichkeit, dass nicht alles reibungslos verläuft. Das Unternehmen wird zweifellos weiterhin Plus- und Plus-Versionen seiner „fortgeschrittenen“ Modelle veröffentlichen, und es besteht die Möglichkeit, dass die Halluzinationsrate weiter steigt.
In diesem Fall muss OpenAI möglicherweise zusätzlich zur weiteren Erforschung der Grundursache eine kurzfristige Lösung anstreben. Schließlich sind diese Modelle einkommensschaffende Produkte Es muss in gebrauchsfähigem Zustand sein. Ich bin kein KI-Wissenschaftler, aber ich denke, meine erste Idee wäre, eine Art Aggregatorprodukt zu erstellen – eine Chat-Schnittstelle, die Zugriff auf mehrere verschiedene OpenAI-Modelle hat.
Wenn Abfragen fortgeschrittene Schlussfolgerungen erfordern, rufen sie GPT-4o auf, und wenn sie die Wahrscheinlichkeit von Halluzinationen verringern möchten, rufen sie ein älteres Modell wie o1 auf. Vielleicht könnte das Unternehmen eleganter vorgehen und verschiedene Modelle verwenden, um sich um verschiedene Elemente einer einzelnen Abfrage zu kümmern, und dann am Ende ein zusätzliches Modell verwenden, um alles zusammenzufassen. Da es sich hierbei im Wesentlichen um eine Teamleistung mehrerer KI-Modelle handeln würde, könnte möglicherweise auch eine Art Faktenprüfungssystem implementiert werden.
Die Erhöhung der Genauigkeitsraten ist jedoch nicht das Hauptziel. Das Hauptziel besteht darin, die Anzahl der Halluzinationen zu verringern. Das bedeutet, dass wir sowohl „Weiß nicht“-Antworten als auch richtige Antworten wertschätzen müssen.
Tatsächlich habe ich keine Ahnung, was OpenAI tun wird oder wie besorgt die Forscher wirklich über die zunehmende Zahl von Halluzinationen sind. Ich weiß nur, dass mehr Halluzinationen schlecht für die Endnutzer sind – sie bedeuten nur mehr Möglichkeiten, uns unbewusst in die Irre zu führen. Wenn Sie ein großer Fan von LLM-Modellen sind, müssen Sie nicht auf sie verzichten – aber lassen Sie nicht zu, dass der Wunsch nach Zeitersparnis die Notwendigkeit der Faktenprüfung der Ergebnisse überlagert. Überprüfen Sie immer die Fakten!
Kommentarfunktion ist geschlossen.